
1. 双列集合
键值对的形式,类似于python中的字典,其中每一个键值对也叫Entry对象。
双列集合的特点
- 双列集合一次需要存一对数据,分别为键和值
- 键不能重复,值可以重复
- 键和值是一一对应的,每一个键只能找到自己对应的值
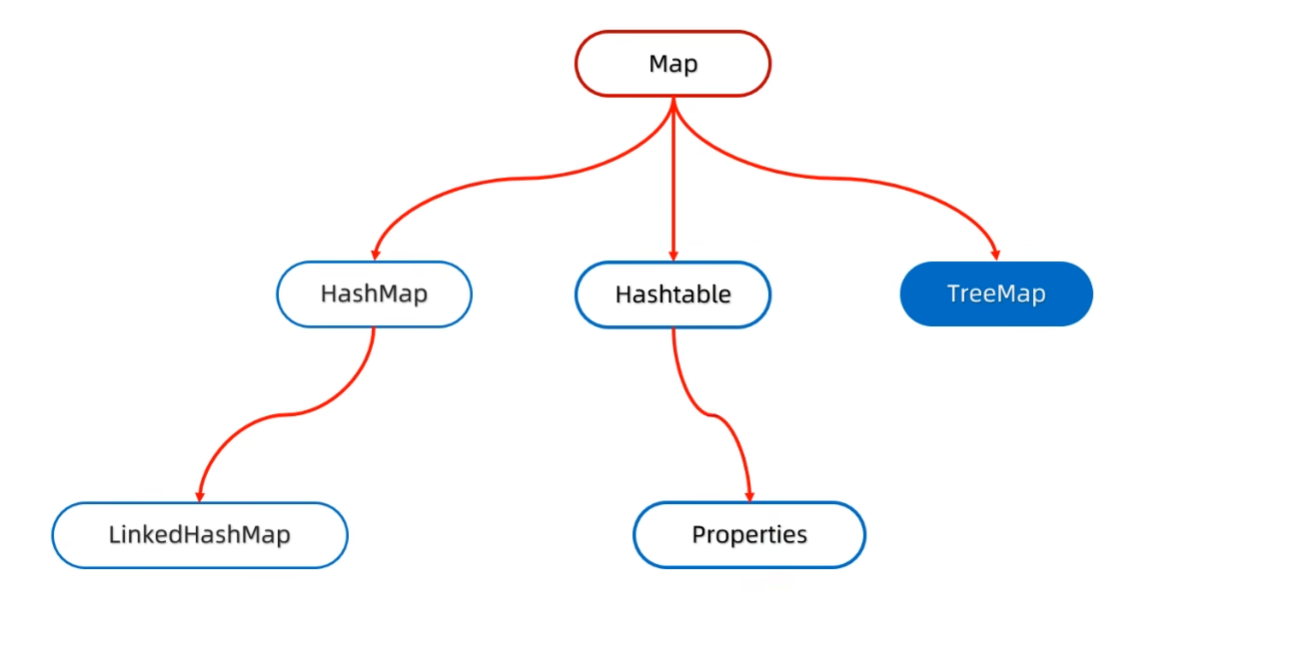
1.1 Map
Map是所有双列集合的顶层接口,他的功能是所有双列集合能使用的。
Map集合的基本接口
| 方法名称 | 说明 |
|---|---|
| V put(K key, V value) | 添加元素 |
| V remove(Object key) | 根据键删除键值对元素 |
| void clear() | 移除所有的键值对元素 |
| boolean containsKey(Object key) | 判断集合是否包含指定的键 |
| boolean containsValue(Object value) | 判断集合是否包含指定的值 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 集合的长度,也就是集合中键值对的个数 |
package Map;
import java.util.HashMap;
import java.util.Map;
public class MapApi {
public static void main(String[] args) {
// 1. 创建Map集合对象
Map<String, String> map = new HashMap<>();
// put方法 添加或覆盖数据
map.put("key1", "value1");
String value = map.put("key1", "value2"); // 覆盖情况下: 返回值是key1对应的value值,如果key1不存在,返回null
System.out.println(value);
// remove方法 删除数据
String removeValue = map.remove("key1");
String removeValue2 = map.remove("key2");
System.out.println(removeValue); // 返回值是删除的value值
System.out.println(removeValue2); // 无该删除的项 返回值是null
// clear方法 清空数据
map.clear();
// 判断是否包含
boolean containsKey = map.containsKey("key1");
boolean containsValue = map.containsValue("value1");
System.out.println(containsKey);
System.out.println(containsValue);
// 集合是否为空
boolean empty = map.isEmpty();
// 集合的大小
int size = map.size();
// 2. 打印集合
System.out.println(map);
}
}Map的遍历方式
- 通过键找值
- 通过键值对
- 通过lambda表达式
package Map;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.function.BiConsumer;
public class 遍历集合 {
public static void main(String[] args) {
// 1. 创建集合对象
HashMap<String, String> map = new HashMap<>();
// 2. 添加元素
map.put("001", "张三");
map.put("002", "李四");
map.put("003", "王五");
map.put("004", "赵六");
// 第一种遍历方式:通过键找值
Set<String> keySet = map.keySet();
// forEach循环
keySet.forEach(key -> {
String value = map.get(key);
System.out.println(key + "=" + value);
});
// 增强for
for (String key : keySet) { // keySet,将集合中的key值取出来,放到集合中
String value = map.get(key);
System.out.println(key + "=" + value);
}
// 迭代器
keySet.iterator().forEachRemaining(key -> {
String value = map.get(key);
System.out.println(key + "=" + value);
});
Iterator<String> iterator = keySet.iterator();
while (iterator.hasNext()) {
String key = iterator.next();
String value = map.get(key);
System.out.println(key + "=" + value);
}
// 第二种遍历方式:通过键值对对象entrySet
Set<Map.Entry<String, String>> entrySet = map.entrySet();
entrySet.forEach(entry -> {
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "=" + value);
});
// 第三种遍历方式:通过lambda
map.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String key, String value) {
System.out.println(key + "=" + value);
}
});
map.forEach((key, value) -> {
System.out.println(key + "=" + value);
});
}
}1.2 HashMap
注意:HashMap的遍历顺序是不确定的,不能依赖HashMap的顺序
HashMap的特点
- HashMap是Map里面的一个实现类
- 没有额外需要学习的特有方法,直接使用Map里面的方法就可以了
- 特点都是由键决定的:
无序、不重复、无索引 - HashMap跟HashSet底层原理是一模一样的,都是
哈希表结构
- HashMap底层是数据结构 Hash表(哈希表)-CSDN博客
- 依赖hashcode方法和equals方法保证键的唯
- 如果
键存储的是自定义对象,需要重写hashCode和equals方法如果值存储自定义对象,不需要重写hashCode和equals方法
在Java中,
equals()和hashCode()是Object类中定义的两个核心方法,它们的协同工作对对象比较和集合操作至关重要:
equals()方法的作用
- 对象内容比较
用于判断两个对象在逻辑上是否”相等”(内容相等),而非内存地址是否相同。// 默认实现(Object类中的原始方法) public boolean equals(Object obj) { return (this == obj); // 仅比较引用地址 }
- 典型使用场景
- 集合类操作(如
List.contains()、Map.containsKey())- 对象比较逻辑定制(如比较用户ID是否相同)
hashCode()方法的作用
- 生成哈希码
返回对象的哈希值(整数),用于确定对象在哈希表结构(如HashMap、HashSet)中的存储位置。// 默认实现(Object类中的原始方法) public native int hashCode(); // 通常基于内存地址生成
- 性能优化
哈希表通过哈希码快速定位对象,时间复杂度可降低到接近O(1)。
/* Student.java */
package Map;
import java.util.Objects;
public class Student {
private String name;
private String sex;
public Student() {
}
public Student(String name, String sex) {
this.name = name;
this.sex = sex;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return Objects.equals(name, student.name) && Objects.equals(sex, student.sex);
}
@Override
public int hashCode() {
return Objects.hash(name, sex);
}
public String toString() {
return "Student{name = " + name + ", sex = " + sex + "}";
}
}练习案例
package Map;
import java.util.*;
public class 练习案例 {
public static void main(String[] args) {
String landscape[] = {"景点A", "景点B", "景点C", "景点D"};
ArrayList<String> list = new ArrayList<>();
Random random = new Random();
for (int i = 0; i < 80; i++) { // 假设80人投票
int index = random.nextInt(landscape.length);
// System.out.println(landscape[index]);
list.add(landscape[index]);
}
// 1. 创建一个Map集合,键是景点名称,值是景点的票数
/*
* 这种情景下不关心到底是谁投了哪个景点,只需要统计每个景点的票数即可
* */
Map<String, Integer> map = new HashMap<>();
for (String s : list) {
if (map.containsKey(s)) {
Integer value = map.get(s);
value++;
map.put(s, value);
} else {
map.put(s, 1);
}
}
// 2. 打印投票结果
List<String> maxScenes = new ArrayList<>();
int max = Integer.MIN_VALUE;
for (Map.Entry<String, Integer> entry : map.entrySet()) {
int currentValue = entry.getValue();
if (currentValue > max) {
// 发现更大的值,重置数据
max = currentValue;
maxScenes.clear();
maxScenes.add(entry.getKey());
} else if (currentValue == max) {
// 相同最大值,追加到列表
maxScenes.add(entry.getKey());
}
}
System.out.println("最高票数:" + max);
System.out.println("获奖景点:" + maxScenes);
}
}1.3 LinkedHashMap
- 由键决定:有序、不重复、无索引。
- 这里的有序指的是
保证存储和取出的元素顺序一致 原理:底层数据结构是依然哈希表,只是每个键值对元素又额外的多了一个双链表的机制记录存储的顺序。
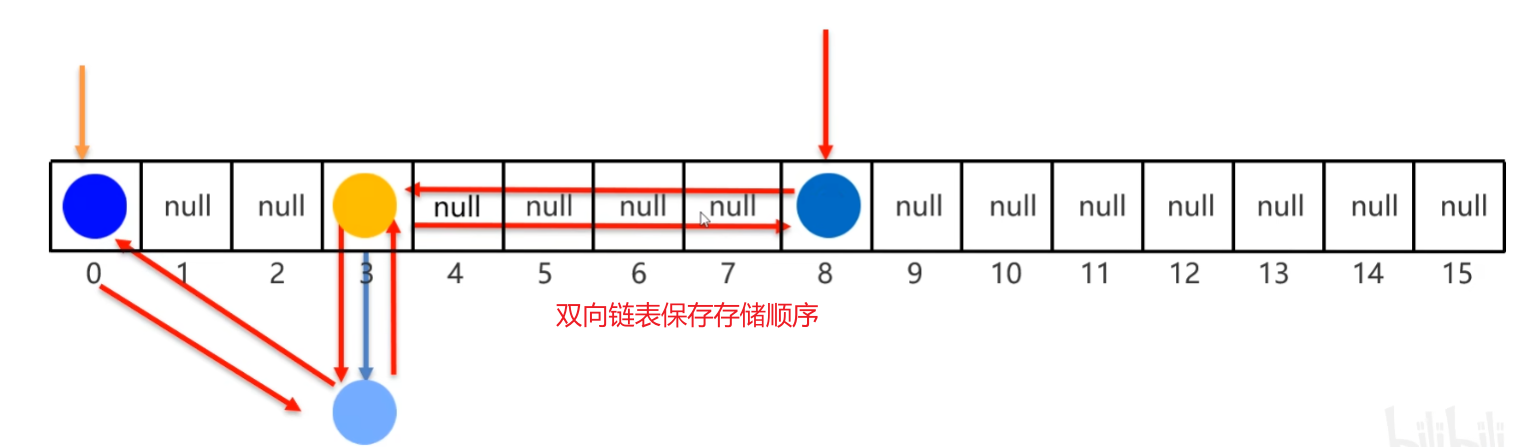
package Map;
import java.util.LinkedHashMap;
public class LinkedHashMapApi {
public static void main(String[] args) {
// 1. 创建LinkedHashMap集合
LinkedHashMap<String, String> lhm = new LinkedHashMap<>();
// 2. 添加元素
lhm.put("张三", "北京");
lhm.put("张三", "南京"); // 键相同,值覆盖
lhm.put("李四", "上海");
lhm.put("王五", "广州");
System.out.println(lhm);
}
}1.4 TreeMap(有序)
- TreeMap跟TreeSet底层原理一样,都是红黑树结构的。
- 由键决定特性:
不重复、无索引、可排序 - 可排序: 对键进行排序,默认输出从小到大排序
- 注意:
默认按照键的从小到大进行排序,也可以自己规定键的排序规则
- 注意:
代码书写两种排序规则
- 创建集合时传递Comparator比较器对象,指定比较规则。
- 自定义类实现Comparable接口指定比较规则。
package Map;
import java.util.Comparator;
import java.util.TreeMap;
public class TreeMapApi {
public static void main(String[] args)
{
//创建集合对象
TreeMap<Integer,String> tm = new TreeMap<Integer,String>(new Comparator<Integer>() { // Comparator比较器对象
@Override
public int compare(Integer o1, Integer o2) {
// o1 : 当前要添加的元素
// o2 : 当前已经存在的元素
return o2 - o1;
}
});
// Integer Double等内置对象都是默认按照升序排列的
// String 是默认按照ASCII排序的
//创建对象
tm.put(21,"迪丽热巴");
tm.put(22,"古力娜扎");
tm.put(18,"柳岩");
tm.put(19,"关晓彤");
tm.put(20,"鞠婧祎");
for (Integer i : tm.keySet()) {
System.out.println(i + " " + tm.get(i));
}
}
}Teacher.java
package Map;
public class Teacher implements Comparable<Teacher> {
private String name;
private int age;
public Teacher() {
}
public Teacher(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String toString() {
return "Teacher{name = " + name + ", age = " + age + "}";
}
@Override
public int compareTo(Teacher o) {
// 按照年龄的升序排列,年龄一样按照姓名的字母排列,同姓名年龄视为同一个人。
// this:表示当前要添加的元素
// o:表示已经在红黑树中存在的元素
// 返回值:
// 负数:表示当前要添加的元素是小的,存左边
// 正数:表示当前要添加的元素是大的,存右边
// 0:表示当前要添加的元素已经存在,舍弃
int i = this.getAge() - o.getAge();
// 年龄相同,调用String的compareTo方法进行比较(按ASCII升序排序)
i = i == 0 ? this.getName().compareTo(o.getName()) : i;
return i;
}
}package Map;
import java.util.TreeMap;
public class TreeMap存储自定义对象 {
public static void main(String[] args) {
Teacher t3 = new Teacher("王五", 22);
Teacher t2 = new Teacher("李四", 21);
Teacher t1 = new Teacher("张三", 20);
Teacher t4 = new Teacher("赵六", 23);
// 创建TreeMap集合
TreeMap<Teacher, String> tm = new TreeMap<Teacher, String>();
tm.put(t1, "Java");
tm.put(t2, "C++");
tm.put(t3, "Python");
tm.put(t4, "JavaScript");
// Teacher类中自定义了Comparable接口,所以TreeMap集合会按照Teacher类中compareTo方法进行排序
System.out.println(tm);
}
}1.5 HashMap源码解读
1.看源码之前需要了解的一些内容
Node<K,V>[] table 哈希表结构中数组的名字
DEFAULT_INITIAL_CAPACITY: 数组默认长度16
DEFAULT_LOAD_FACTOR: 默认加载因子0.75
HashMap里面每一个对象包含以下内容:
1.1 链表中的键值对对象
包含:
int hash; //键的哈希值
final K key; //键
V value; //值
Node<K,V> next; //下一个节点的地址值
1.2 红黑树中的键值对对象
包含:
int hash; //键的哈希值
final K key; //键
V value; //值
TreeNode<K,V> parent; //父节点的地址值
TreeNode<K,V> left; //左子节点的地址值
TreeNode<K,V> right; //右子节点的地址值
boolean red; //节点的颜色
2.添加元素
HashMap<String,Integer> hm = new HashMap<>();
hm.put("aaa" , 111);
hm.put("bbb" , 222);
hm.put("ccc" , 333);
hm.put("ddd" , 444);
hm.put("eee" , 555);
添加元素的时候至少考虑三种情况:
2.1数组位置为null
2.2数组位置不为null,键不重复,挂在下面形成链表或者红黑树
2.3数组位置不为null,键重复,元素覆盖
//参数一:键
//参数二:值
//返回值:被覆盖元素的值,如果没有覆盖,返回null
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//利用键计算出对应的哈希值,再把哈希值进行一些额外的处理
//简单理解:返回值就是返回键的哈希值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//参数一:键的哈希值
//参数二:键
//参数三:值
//参数四:如果键重复了是否保留
// true,表示老元素的值保留,不会覆盖
// false,表示老元素的值不保留,会进行覆盖
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
//定义一个局部变量,用来记录哈希表中数组的地址值。
Node<K,V>[] tab;
//临时的第三方变量,用来记录键值对对象的地址值
Node<K,V> p;
//表示当前数组的长度
int n;
//表示索引
int i;
//把哈希表中数组的地址值,赋值给局部变量tab
tab = table;
if (tab == null || (n = tab.length) == 0){
//1.如果当前是第一次添加数据,底层会创建一个默认长度为16,加载因子为0.75的数组
//2.如果不是第一次添加数据,会看数组中的元素是否达到了扩容的条件
//如果没有达到扩容条件,底层不会做任何操作
//如果达到了扩容条件,底层会把数组扩容为原先的两倍,并把数据全部转移到新的哈希表中
tab = resize();
//表示把当前数组的长度赋值给n
n = tab.length;
}
//拿着数组的长度跟键的哈希值进行计算,计算出当前键值对对象,在数组中应存入的位置
i = (n - 1) & hash;//index
//获取数组中对应元素的数据
p = tab[i];
if (p == null){
//底层会创建一个键值对对象,直接放到数组当中
tab[i] = newNode(hash, key, value, null);
}else {
Node<K,V> e;
K k;
//等号的左边:数组中键值对的哈希值
//等号的右边:当前要添加键值对的哈希值
//如果键不一样,此时返回false
//如果键一样,返回true
boolean b1 = p.hash == hash;
if (b1 && ((k = p.key) == key || (key != null && key.equals(k)))){
e = p;
} else if (p instanceof TreeNode){
//判断数组中获取出来的键值对是不是红黑树中的节点
//如果是,则调用方法putTreeVal,把当前的节点按照红黑树的规则添加到树当中。
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
} else {
//如果从数组中获取出来的键值对不是红黑树中的节点
//表示此时下面挂的是链表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//此时就会创建一个新的节点,挂在下面形成链表
p.next = newNode(hash, key, value, null);
//判断当前链表长度是否超过8,如果超过8,就会调用方法treeifyBin
//treeifyBin方法的底层还会继续判断
//判断数组的长度是否大于等于64
//如果同时满足这两个条件,就会把这个链表转成红黑树
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
//e: 0x0044 ddd 444
//要添加的元素: 0x0055 ddd 555
//如果哈希值一样,就会调用equals方法比较内部的属性值是否相同
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))){
break;
}
p = e;
}
}
//如果e为null,表示当前不需要覆盖任何元素
//如果e不为null,表示当前的键是一样的,值会被覆盖
//e:0x0044 ddd 555
//要添加的元素: 0x0055 ddd 555
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null){
//等号的右边:当前要添加的值
//等号的左边:0x0044的值
e.value = value;
}
afterNodeAccess(e);
return oldValue;
}
}
//threshold:记录的就是数组的长度 * 0.75,哈希表的扩容时机 16 * 0.75 = 12
if (++size > threshold){
resize();
}
//表示当前没有覆盖任何元素,返回null
return null;
}
1.6 TreeMap源码解读

1.TreeMap中每一个节点的内部属性
K key; //键
V value; //值
Entry<K,V> left; //左子节点
Entry<K,V> right; //右子节点
Entry<K,V> parent; //父节点
boolean color; //节点的颜色
2.TreeMap类中中要知道的一些成员变量
public class TreeMap<K,V>{
//比较器对象
private final Comparator<? super K> comparator;
//根节点
private transient Entry<K,V> root;
//集合的长度
private transient int size = 0;
3.空参构造
//空参构造就是没有传递比较器对象
public TreeMap() {
comparator = null;
}
4.带参构造
//带参构造就是传递了比较器对象。
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
5.添加元素
public V put(K key, V value) {
return put(key, value, true);
}
参数一:键
参数二:值
参数三:当键重复的时候,是否需要覆盖值
true:覆盖
false:不覆盖
private V put(K key, V value, boolean replaceOld) {
//获取根节点的地址值,赋值给局部变量t
Entry<K,V> t = root;
//判断根节点是否为null
//如果为null,表示当前是第一次添加,会把当前要添加的元素,当做根节点
//如果不为null,表示当前不是第一次添加,跳过这个判断继续执行下面的代码
if (t == null) {
//方法的底层,会创建一个Entry对象,把他当做根节点
addEntryToEmptyMap(key, value);
//表示此时没有覆盖任何的元素
return null;
}
//表示两个元素的键比较之后的结果
int cmp;
//表示当前要添加节点的父节点
Entry<K,V> parent;
//表示当前的比较规则
//如果我们是采取默认的自然排序,那么此时comparator记录的是null,cpr记录的也是null
//如果我们是采取比较去排序方式,那么此时comparator记录的是就是比较器
Comparator<? super K> cpr = comparator;
//表示判断当前是否有比较器对象
//如果传递了比较器对象,就执行if里面的代码,此时以比较器的规则为准
//如果没有传递比较器对象,就执行else里面的代码,此时以自然排序的规则为准
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else {
V oldValue = t.value;
if (replaceOld || oldValue == null) {
t.value = value;
}
return oldValue;
}
} while (t != null);
} else {
//把键进行强转,强转成Comparable类型的
//要求:键必须要实现Comparable接口,如果没有实现这个接口
//此时在强转的时候,就会报错。
Comparable<? super K> k = (Comparable<? super K>) key;
do {
//把根节点当做当前节点的父节点
parent = t;
//调用compareTo方法,比较根节点和当前要添加节点的大小关系
cmp = k.compareTo(t.key);
if (cmp < 0)
//如果比较的结果为负数
//那么继续到根节点的左边去找
t = t.left;
else if (cmp > 0)
//如果比较的结果为正数
//那么继续到根节点的右边去找
t = t.right;
else {
//如果比较的结果为0,会覆盖
V oldValue = t.value;
if (replaceOld || oldValue == null) {
t.value = value;
}
return oldValue;
}
} while (t != null);
}
//就会把当前节点按照指定的规则进行添加
addEntry(key, value, parent, cmp < 0);
return null;
}
private void addEntry(K key, V value, Entry<K, V> parent, boolean addToLeft) {
Entry<K,V> e = new Entry<>(key, value, parent);
if (addToLeft)
parent.left = e;
else
parent.right = e;
//添加完毕之后,需要按照红黑树的规则进行调整
fixAfterInsertion(e);
size++;
modCount++;
}
private void fixAfterInsertion(Entry<K,V> x) {
//因为红黑树的节点默认就是红色的
x.color = RED;
//按照红黑规则进行调整
//parentOf:获取x的父节点
//parentOf(parentOf(x)):获取x的爷爷节点
//leftOf:获取左子节点
while (x != null && x != root && x.parent.color == RED) {
//判断当前节点的父节点是爷爷节点的左子节点还是右子节点
//目的:为了获取当前节点的叔叔节点
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
//表示当前节点的父节点是爷爷节点的左子节点
//那么下面就可以用rightOf获取到当前节点的叔叔节点
Entry<K,V> y = rightOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
//叔叔节点为红色的处理方案
//把父节点设置为黑色
setColor(parentOf(x), BLACK);
//把叔叔节点设置为黑色
setColor(y, BLACK);
//把爷爷节点设置为红色
setColor(parentOf(parentOf(x)), RED);
//把爷爷节点设置为当前节点
x = parentOf(parentOf(x));
} else {
//叔叔节点为黑色的处理方案
//表示判断当前节点是否为父节点的右子节点
if (x == rightOf(parentOf(x))) {
//表示当前节点是父节点的右子节点
x = parentOf(x);
//左旋
rotateLeft(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateRight(parentOf(parentOf(x)));
}
} else {
//表示当前节点的父节点是爷爷节点的右子节点
//那么下面就可以用leftOf获取到当前节点的叔叔节点
Entry<K,V> y = leftOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
if (x == leftOf(parentOf(x))) {
x = parentOf(x);
rotateRight(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateLeft(parentOf(parentOf(x)));
}
}
}
//把根节点设置为黑色
root.color = BLACK;
}
6.课堂思考问题:
6.1TreeMap添加元素的时候,键是否需要重写hashCode和equals方法?
此时是不需要重写的。
6.2HashMap是哈希表结构的,JDK8开始由数组,链表,红黑树组成的。
既然有红黑树,HashMap的键是否需要实现Compareable接口或者传递比较器对象呢?
不需要的。
因为在HashMap的底层,默认是利用哈希值的大小关系来创建红黑树的
6.3TreeMap和HashMap谁的效率更高?
如果是最坏情况,添加了8个元素,这8个元素形成了链表,此时TreeMap的效率要更高
但是这种情况出现的几率非常的少。
一般而言,还是HashMap的效率要更高。
6.4你觉得在Map集合中,java会提供一个如果键重复了,不会覆盖的put方法呢?
此时putIfAbsent本身不重要。
传递一个思想:
代码中的逻辑都有两面性,如果我们只知道了其中的A面,而且代码中还发现了有变量可以控制两面性的发生。
那么该逻辑一定会有B面。
习惯:
boolean类型的变量控制,一般只有AB两面,因为boolean只有两个值
int类型的变量控制,一般至少有三面,因为int可以取多个值。
6.5三种双列集合,以后如何选择?
HashMap LinkedHashMap TreeMap
默认:HashMap(效率最高)
如果要保证存取有序:LinkedHashMap
如果要进行排序:TreeMap2. 可变参数
- 可变参数最多只能有一个
- 假如函数参数中还有其他形参,可变参数必须放在最后面
package Map;
public class 可变参数 {
public static void main(String[] args) {
System.out.println(getSum(1,2,3));
test("zhangsan","bmw","benz","audi");
}
public static int getSum(int...args){
// 其实内部是一个数组,只不过是java帮我们创建的
System.out.println(args); // [I@776ec8df 数组的地址类型[表示数组 I表示int类型 @表示地址
System.out.println(args.length);
int sum = 0;
for (int i = 0; i < args.length; i++) {
sum += args[i];
}
return sum;
}
// 可变参数的细节
// 1. 可变参数最多只能有一个
// public static void test(int...args1,int...args2){ } error
// 2. 可变参数必须放在参数列表的最后面
public static void test(String name,String...cars){
System.out.print(name + " has");
for (int i = 0; i < cars.length; i++) {
System.out.print(" " + cars[i]);
}
}
}3. Collections
java.util.Collections:是集合工具类作用:Collections不是集合,而是集合的工具类
| 方法名称 | 说明 |
|---|---|
public static <T> boolean addAll(Collection<T> c, T... elements) |
批量添加元素 |
public static void shuffle(List<?> list) |
打乱List集合元素的顺序 |
public static <T> void sort(List<T> list) |
排序 |
public static <T> void sort(List<T> list, Comparator<T> c) |
根据指定的规则进行排序 |
public static <T> int binarySearch (List<T> list, T key) |
以二分查找法查找元素 |
public static <T> void copy(List<T> dest, List<T> src) |
拷贝集合中的元素 |
public static <T> int fill (List<T> list, T obj) |
使用指定的元素填充集合 |
public static <T> void max/min(Collection<T> coll) |
根据默认的自然排序获取最大/小值 |
public static <T> void swap(List<?> list, int i, int j) |
交换集合中指定位置的元素 |
package Collections;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class CollectionsApi {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
// 1. 批量
Collections.addAll(list, "Joke", "Loris", "Lucky", "Dave", "Jam");
// 2. 打乱
Collections.shuffle(list);
// 3. 排序
Collections.sort(list);
Comparator<String> comparator = new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o2.length() - o1.length();
}
};
// 自定义排序
Collections.sort(list, comparator);
// 4. 二分查找 注意:要么是自然排序的集合
// 假如要传入自定义排序过的list,binarySearch方法第二个参数传入自定义排序器
int index = Collections.binarySearch(list, "Loris", comparator); // 返回值为索引
System.out.println(index);
// 5. fill 填充
List<String> list2 = new ArrayList<>();
Collections.addAll(list2, " ", " ", " ", " ", " ", " ", " ", " ", " ", " ");
Collections.fill(list2, "Joke");
// 6. swap
System.out.println("交换前" + list);
Collections.swap(list, 0, 1);
System.out.println(list);
System.out.println(list2);
}
}4. 综合练习
4.1 洗牌功能(打乱)
import java.util.ArrayList;
import java.util.Collections;
public class PokerGame {
// 总牌
private static final ArrayList<Poker> pokers;
private static ArrayList<Player> players;
// 静态代码块: 在类加载时执行,只执行一次
static {
String[] color = {"♥", "♦", "♣", "♠"};
String[] number = {"3", "4", "5", "6", "7", "8", "9", "10", "J", "Q", "K", "A", "2"};
// 牌盒
pokers = new ArrayList<>();
for (String c : color) {
for (String num : number) {
Poker poker = new Poker(c, num, false, false);
pokers.add(poker);
}
}
pokers.add(new Poker("", "", true, false));
pokers.add(new Poker("", "", false, true));
}
public PokerGame() {
System.out.println("游戏开始");
System.out.println("洗牌");
// 洗牌
Collections.shuffle(pokers);
// 发牌
players = new ArrayList<>();
Player player1 = new Player("张三");
Player player2 = new Player("李四");
Player player3 = new Player("王五");
ArrayList<Poker> p1 = new ArrayList<>();
ArrayList<Poker> p2 = new ArrayList<>();
ArrayList<Poker> p3 = new ArrayList<>();
ArrayList<Poker> lord = new ArrayList<>(); // 底牌(地主牌)
for (int i = 0; i < pokers.size(); i++) {
Poker poker = pokers.get(i);
if (i >= pokers.size() - 3) {
lord.add(poker);
} else if (i % 3 == 0) {
p1.add(poker);
} else if (i % 3 == 1) {
p2.add(poker);
} else {
p3.add(poker);
}
}
// 玩家牌
player1.setPokers(p1);
player2.setPokers(p2);
player3.setPokers(p3);
players.add(player1);
players.add(player2);
players.add(player3);
player1.printPokers();
player2.printPokers();
player3.printPokers();
System.out.print("底牌: ");
for (Poker poker : lord) {
System.out.print(poker + " ");
}
}
public void start() {
}
}4.2 排序功能(玩家手上的牌自动排序)
首先要找出牌面值和价值之间的关系,我选择在Poker类的构造方法中初始化牌价值
public class Poker {
private String color;
private String number;
private boolean isBigJoker = false;
private boolean isSmallJoker = false;
private int pokerValue;
public Poker() {}
/*
* 扑克牌的数字和对应牌的大小的关系是
* 3 -- 1 4 -- 2 5 -- 3 6 -- 4 7 -- 5 8 -- 6 9 -- 7 10 -- 8 J -- 9 Q -- 10 K -- 11 A -- 12
* 2 -- 13 小王 -- 14 大王 -- 15
* */
public Poker(String color, String number, boolean isBigJoker, boolean isSmallJoker) {
this.color = color;
this.number = number;
this.isBigJoker = isBigJoker;
this.isSmallJoker = isSmallJoker;
this.pokerValue = initPokerValue();
}
public String getColor() {
return color;
}
public void setColor(String color) {
this.color = color;
}
public String getNumber() {
return number;
}
public void setNumber(String number) {
this.number = number;
}
public boolean isIsBigJoker() {
return isBigJoker;
}
public void setIsBigJoker(boolean isBigJoker) {
this.isBigJoker = isBigJoker;
}
public boolean isIsSmallJoker() {
return isSmallJoker;
}
public void setIsSmallJoker(boolean isSmallJoker) {
this.isSmallJoker = isSmallJoker;
}
public int getPokerValue() {
return pokerValue;
}
public String toString() {
if (isBigJoker) {
return "大王";
} else if (isSmallJoker) {
return "小王";
} else {
return color + number;
}
}
private int initPokerValue() {
if (isBigJoker) {
return 15;
} else if (isSmallJoker) {
return 14;
} else if (number.equals("J")) {
return 9;
} else if (number.equals("Q")) {
return 10;
} else if (number.equals("K")) {
return 11;
} else if (number.equals("A")) {
return 12;
} else if (number.equals("2")) {
return 13;
} else {
return Integer.parseInt(number) - 2;
}
}
}后面排序的时候按照pokerValue排序就行了
import java.util.Comparator;
public class Tool {
public static Comparator<Poker> comparator = new Comparator<Poker>() {
@Override
public int compare(Poker o1, Poker o2) {
return o1.getPokerValue() - o2.getPokerValue();
}
};
}4.3 登陆界面
package UI;
import javafx.application.Application;
import javafx.application.Platform;
import javafx.geometry.Insets;
import javafx.geometry.Pos;
import javafx.scene.Scene;
import javafx.scene.control.*;
import javafx.scene.image.Image;
import javafx.scene.image.ImageView;
import javafx.scene.layout.*;
import javafx.stage.Modality;
import javafx.stage.Stage;
public class LoginDialog {
private Stage loginDialog;
private MainGame mainGame;
public LoginDialog(Stage parentStage) {
// 创建登录对话框
loginDialog = new Stage();
loginDialog.initOwner(parentStage);
loginDialog.setTitle("斗地主登录");
loginDialog.initModality(Modality.APPLICATION_MODAL);
loginDialog.setResizable(false);
// 使用StackPane实现背景铺满 StackPane的特性:
// 默认会拉伸子节点到容器大小(需子节点允许拉伸)
// 通过setAlignment()可调整子节点对齐方式
// 多个子节点共享同一个布局空间
StackPane rootPane = new StackPane();
// 加载背景图片(使用相对路径)
Image backgroundImage = new Image("/image/login/background.png");
ImageView backgroundImageView = new ImageView(backgroundImage);
// 设置背景图片的尺寸为400x300
backgroundImageView.setFitWidth(440);
backgroundImageView.setFitHeight(300);
// 创建主内容容器
VBox mainContent = new VBox(20);
mainContent.setAlignment(Pos.CENTER);
mainContent.setPadding(new Insets(20));
// 创建登录表单
GridPane gridPane = createLoginForm();
// 创建按钮容器
HBox buttonBox = createButtonBox(loginDialog);
mainContent.getChildren().addAll(gridPane, buttonBox);
mainContent.setAlignment(Pos.TOP_CENTER);
// 将元素添加到根面板
rootPane.getChildren().addAll(backgroundImageView, mainContent);
// 设置场景
Scene scene = new Scene(rootPane, 440, 300);
loginDialog.setScene(scene);
loginDialog.centerOnScreen();
// 显示对话框
loginDialog.showAndWait();
}
private GridPane createLoginForm() {
GridPane gridPane = new GridPane();
gridPane.setHgap(10);
gridPane.setVgap(10);
gridPane.setPadding(new Insets(20));
gridPane.setAlignment(Pos.CENTER);
// 用户名输入
TextField usernameField = new TextField();
usernameField.setPromptText("请输入用户名");
usernameField.setPrefWidth(200);
// 密码输入
PasswordField passwordField = new PasswordField();
passwordField.setPromptText("请输入密码");
// 选项复选框
CheckBox rememberPassword = new CheckBox("记住密码");
CheckBox autoLogin = new CheckBox("自动登录");
HBox optionsBox = new HBox(10, rememberPassword, autoLogin);
// 添加组件到网格
gridPane.add(new Label("用户名:"), 0, 0);
gridPane.add(usernameField, 1, 0);
gridPane.add(new Label("密码:"), 0, 1);
gridPane.add(passwordField, 1, 1);
gridPane.add(optionsBox, 1, 2);
return gridPane;
}
private HBox createButtonBox(Stage loginDialog) {
Button loginButton = new Button("登录");
Button registerButton = new Button("注册");
HBox buttonBox = new HBox(20, loginButton, registerButton);
buttonBox.setAlignment(Pos.CENTER);
// 登录按钮事件
loginButton.setOnAction(e -> handleLogin(loginDialog));
// 注册按钮事件
registerButton.setOnAction(e -> showRegistrationDialog());
return buttonBox;
}
private void handleLogin(Stage loginDialog) {
// 获取账号密码
String username = "admin";
boolean loginSuccess = true; // 模拟成功
if (loginSuccess) {
loginDialog.close();
Platform.runLater(() -> {
MainGame game = new MainGame((Stage) loginDialog.getOwner());
game.show();
});
}
}
private void showMainInterface() {
}
private void showRegistrationDialog() {
}
private void showAlert(String title, String message) {
Alert alert = new Alert(Alert.AlertType.ERROR);
alert.setTitle(title);
alert.setHeaderText(null);
alert.setContentText(message);
alert.showAndWait();
}
}5. 集合进阶
5.1 不可变集合
不可变集合就是不能对集合进行操作的集合
创建不可变集合的应用场景
- 如果某个数据不能被修改,把它防御性地拷贝到不可变集合中是个很好的实践。
- 或者当集合对象被不可信的库调用时,不可变形式是安全的。
5.2 创建不可变集合的书写方式
在List、Set、Map接口中,都存在静态的of方法,可以获取一个不可变的集合。
| 方法名称 | 说明 |
|---|---|
static <E> List<E> of(E...elements) |
创建一个具有指定元素的List集合对象 |
static <E> Set<E> of(E...elements) |
创建一个具有指定元素的Set集合对象 |
static <K, V> Map<K, V> of(E...elements) |
创建一个具有指定元素的Map集合对象 |
返回的不可变集合是不能删除、插入、修改操作的
package 不可变集合;
import java.util.Iterator;
import java.util.List;
public class immutableList {
public static void main(String[] args) {
List<String> list = List.of("a", "b", "c");
for (String s : list) {
System.out.println(s);
}
System.out.println("----------------------");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String s = iterator.next();
System.out.println(s);
}
System.out.println("-----------------------");
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
// list.add("d");
// list.remove("a");
// list.set(0,"d");
System.out.println(list);
}
}package 不可变集合;
import java.util.Map;
import java.util.Set;
public class immutableMap {
public static void main(String[] args) {
Map<String, String> hm = Map.of("张三", "a", "李四", "b");
hm.forEach((k, v) -> {
System.out.println(k + "=" + v);
});
// hm.remove("张三");
// System.out.println(hm);
//获取到所有的键值对对象(Entry对象)放到一个集合中
Set<Map.Entry<String, String>> entries = hm.entrySet();
//把entries变成一个数组
Map.Entry[] arr = entries.toArray(new Map.Entry[0]); // new Map.Entry[0]传入一个空Entry数组
// 判断传入数组长度是否足够。如果不够,创建新数组;如果足够,使用传入的数组填充。最后返回数组
Map map = Map.ofEntries(arr);
map.put("王五", "c");
System.out.println(map);
// copyof方法实际上就是上述操作返回一个不可变的集合
Map<String, String> map1 = Map.copyOf(hm);
Object[] objects = entries.toArray(); // 将键值对集合变成一个数组,toArray()没有参数时返回一个Object数组
for (Object object : objects) {
System.out.println(object);
}
}
}
6. Stream流
Stream流的作用:结合了Lambda表达式,简化集合、数组的操作
Stream流的使用步骤:
- 先得到一条Stream流(流水线),并把数据放上去
- 利用stream流中的API进行各种操作
中间方法:可以链式调用的方法
终结方法:无返回对象,不能链式调用
| 获取方式 | 方法名 | 说明 |
|---|---|---|
| 单列集合 | default Stream |
Collection中的默认方法 |
| 双列集合 | 无 | 无法直接使用stream流 |
| 数组 | public static |
Arrays工具类中的静态方法 |
| 一堆零散数据 | public static |
Stream接口中的静态方法 |
package stream流;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.stream.Stream;
public class StreamDemo_1 {
public static void main(String[] args) {
// 1. 单列集合获取流对象
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "Joke", "Loris", "Lucky");
list.stream().forEach(System.out::println);
Stream<String> stream = list.stream();
// 2. 双列集合
HashMap<String, String> map = new HashMap<>();
map.put("China", "北京");
map.put("America", "Washington");
map.put("England", "London");
Stream<String> stream = map.keySet().stream();
stream.forEach(s->{
System.out.println(s + ":" + map.get(s));
});
map.entrySet().stream().forEach(System.out::println);
// 3. 普通数组
int [] arr = {1, 2, 3, 4, 5, 6, 7, 8, 9};
Arrays.stream(arr).forEach(System.out::println);
// 引用数据类型的数组
String [] arr2 = {"Joke", "Loris", "Lucky"};
Stream<String> stream2 = Arrays.stream(arr2);
stream2.forEach(System.out::println);
// 4. 零散数据
Stream.of("Joke", "Loris", "Lucky").forEach(System.out::println);
// 注意 stream.of方法可以接收数组,但是会当作一个元素,而不是将数组里面的元素作为参数
Stream.of(arr).forEach(System.out::println); // [I@2f4d3709
}
}6.1 Stream的中间方法
| 名称 | 说明 |
|---|---|
| Stream |
过滤 |
| Stream |
获取前几个元素 |
| Stream |
跳过前几个元素 |
| Stream |
元素去重,依赖(hashCode和equals方法) |
| static |
合并a和b两个流为一个流 |
| Stream |
转换流中的数据类型 |
注意1: 中间方法,返回新的Stream流,原来的Stream流只能使用一次,建议使用链式编程
注意2: 修改Stream流中的数据,不会影响原来集合或者数组中的数据
package stream流;
import java.util.ArrayList;
import java.util.Collections;
import java.util.stream.Stream;
public class 中间方法 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "Joke", "Joke", "Loris", "Lucky", "Dave", "Jam");
// 错误,stream流只能被使用一次,使用完后就会被关闭
// Stream<String> stream = list.stream();
// Stream<String> stream1 = stream.filter(s -> s.startsWith("J"));
// stream1.forEach(System.out::println);
// Stream<String> stream2 = stream.filter(s -> s.startsWith("L"));
list.stream()
.filter(s -> s.startsWith("J")) // 过滤出以J开头的元素
.forEach(System.out::println);
// limit
list.stream()
.limit(2)
.forEach(System.out::println);
// skip
list.stream()
.skip(2)
.forEach(System.out::println);
// distinct方法 去重
list.stream()
.distinct()
.forEach(System.out::println);
// contact方法 合并流
Stream<String> stream = list.stream();
Stream<String> stream1 = stream.filter(s -> s.startsWith("J"));
Stream<String> stream2 = stream.filter(s -> s.startsWith("L"));
Stream.concat(stream1, stream2).forEach(System.out::println);
// map方法 将流中的元素进行转换,对每一个元素进行一次函数式处理,并返回一个转换后的值
list.stream()
.map(String::toUpperCase)
.forEach(System.out::println);
}
}6.2 终结方法
| 名称 | 说明 |
|---|---|
| void forEach(Consumer action) | 遍历 |
| long count() | 统计 |
| toArray() | 收集流中的数据,放到数组中 |
| collect(Collector collector) | 收集流中的数据,放到集合中 |
package stream流;
import java.util.*;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.function.IntFunction;
import java.util.stream.Collectors;
public class 终结方法 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "Joke", "Loris", "Lucky", "Dave", "Jam");
// 1. void forEach();
list.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
list.stream().forEach(System.out::println);
// long count();
long count = list.stream().count();
System.out.println(count);
//3. toArray()返回一个数组
String[] arr1 = list.stream().toArray(new IntFunction<String[]>() {
@Override
public String[] apply(int value) { // value在toArray中被计算出流的长度然后传递给apply()
return new String[value];
}
});
String[] arr2 = list.stream().toArray(value -> new String[value]);
// 收集到集合中
List<String> newList = list.stream().filter(s -> s.startsWith("L")).collect(Collectors.toList());
Set<String> newList2 = list.stream().filter(s -> s.startsWith("L")).collect(Collectors.toSet());
System.out.println(newList);
System.out.println(newList2);
// 收集到Map中
ArrayList<String> peoList = new ArrayList<>();
Collections.addAll(peoList,"Joke-18","Loris-16","Jerry-25");
/*Map<String,Integer> map = peoList.stream().collect(Collectors.toMap(
// toMap函数接收两个参数Function接口 第一个Function是map中键的规则
new Function<String, String>() { // 第一个泛型是流中的元素类型,第二个泛型是map中键的类型
@Override
public String apply(String s) { // s是流中的元素
return s.split("-")[0]; // 返回的是map中键的值
}
}, new Function<String, Integer>() {
@Override
public Integer apply(String s) {
return Integer.parseInt(s.split("-")[1]);
}
}
));*/
// 和上面等价 注意 Map里面键自然是不能重复的
Map<String,Integer> map = peoList.stream().collect(Collectors.toMap(
s -> s.split("-")[0],
s -> Integer.parseInt(s.split("-")[1])
));
System.out.println(map);
}
}7. 方法引用
把已经有的方法拿过来用,当做函数式接口中抽象方法的方法体。
7.1 方法引用的基本使用
基本要求
- 引用处必须是
函数式接口 - 被引用的方法必须存在
- 被引用方法的形参和返回值需要跟抽象方法保持一致
- 被引用方法的功能要满足当前的需求
package 方法引用;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
public class Demo {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 2, 5, 1, 3, 8, 4, 6);
// 1. 函数式接口
list.sort(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1 - o2;
}
});
// 2. lambda表达式
list.sort((o1, o2) -> o1 - o2);
// 3. 方法引用 :: 是方法引用的符号
list.sort(Integer::compare);
list.sort(Demo::sort_method);
System.out.println(list);
}
public static int sort_method(Integer o1, Integer o2){
return o1 - o2;
}
}7.2 方法引用的分类
引用静态方法
- 格式:
类名::静态方法 - 范例:
Integer::parseInt
引用成员方法 格式:对象::成员方法
其他类:其他类对象::方法名本类:this::方法名 / 本类对象::方法名父类:super::方法名
注意:本类和父类引用处不能是静态方法,因为没有this或者super指针
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.function.Function;
import java.util.stream.Collectors;
public class FunctionDemo {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
Collections.addAll(list, "Joke-11", "Jon-22", "Loris-33", "Lucky-44", "Dave-55");
// List<Student> students = list.stream().map(new Function<String, Student>() {
// @Override
// public Student apply(String s) {
// return new Student(s.split("-")[0], Integer.parseInt(s.split("-")[1]));
// }
// }).collect(Collectors.toList());
List<Student> students = list.stream().map(Student::new).collect(Collectors.toList());
System.out.println(students);
}
}引用构造方法
格式: 类名::new
范例: Student::new
使用类名引用成员方法
格式: 类名::成员方法
范例: String::substring
注意: 引用成员方法的时候,函数式接口的第一个参数是流中的每个元素,都会调用被引用的方法,因此被引用的方法可以没有参数
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.function.Function;
public class FunctionDemo_02 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
Collections.addAll(list,"aaa", "bbb", "ccc", "ddd", "eee");
list.stream().map(new Function<String, String>() {
@Override
public String apply(String s) {
return s.toUpperCase();
}
}).forEach(System.out::println);
list.stream().map(String::toUpperCase).forEach(System.out::println);
}
}引用数组的构造方法
格式: 数据类型[]::new
范例: int[]::new
import java.util.ArrayList;
import java.util.Collections;
import java.util.function.IntFunction;
public class FunctionDemo_03 {
public static void main(String[] args) {
/*
* 将集合中的数据收集到数组中
* */
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list,1,2,3,4,5);
// 收集
Integer[] arr = list.toArray(new IntFunction<Integer[]>() {
@Override
public Integer[] apply(int value) {
return new Integer[value];
}
});
Integer[] arr2 = list.toArray(value -> new Integer[value]);
list.stream().toArray(Integer[]::new);
}
}8. 异常
Java中有一个非常完善的异常处理机制
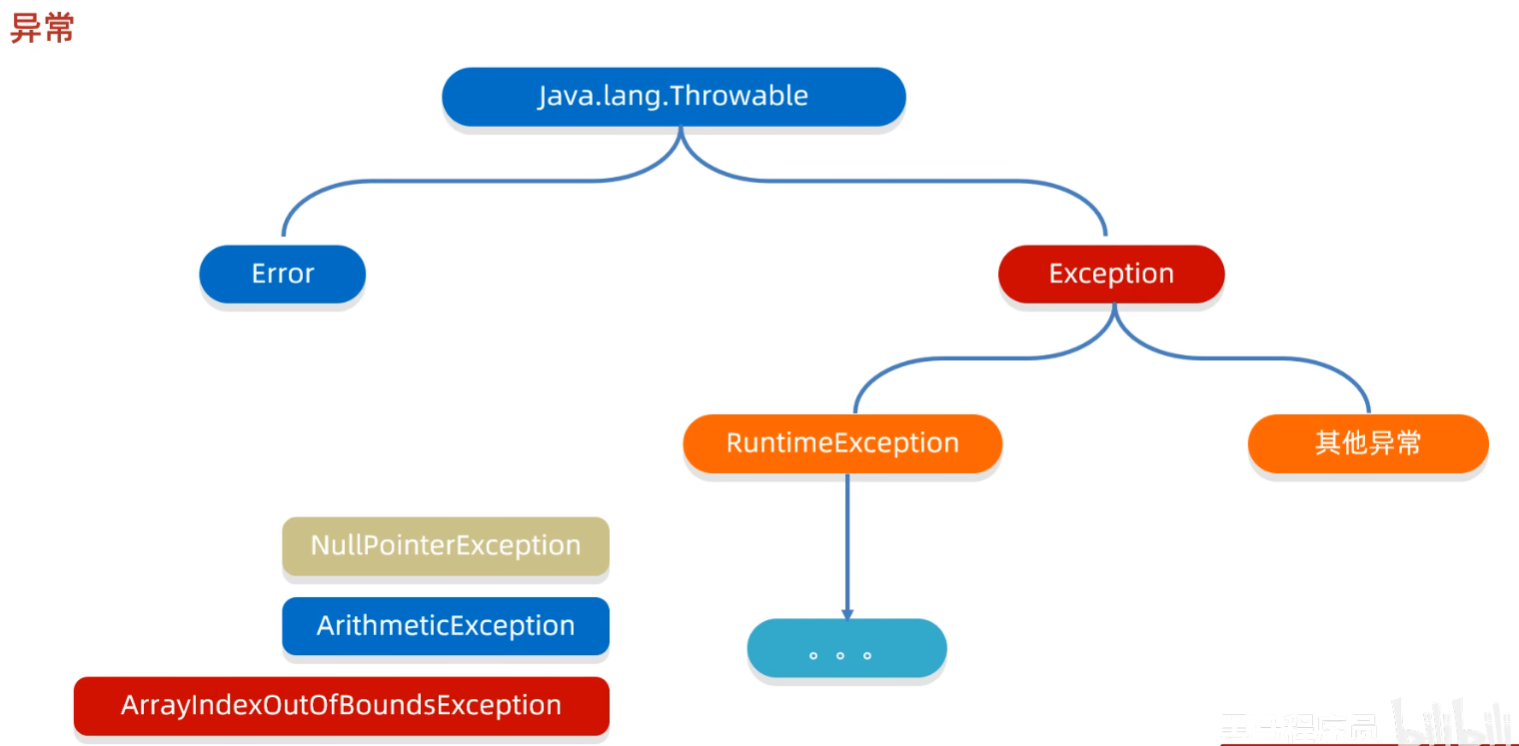
Error: 代表的系统级别错误(属于严重问题),系统一旦出现问题,sun公司会把这些错误封装成Error对象。Error是给sun公司自己用的,不是给我们程序员用的。因此我们开发人员不用管它
Exception: 叫做异常,代表程序可能出现的问题
我们通常会用Exception以及他的子类来封装程序出现的问题
编译时异常: 编译阶段就会出现异常提醒的。(如:日期解析异常)- 没有继承RuntimeExcpetion的异常,
直接继承于Excpetion,编译阶段就会错误提示
- 没有继承RuntimeExcpetion的异常,
运行时异常:RuntimeException及其子类- 运行时出现的异常(如:数组索引越界异常)
- 编译阶段不会出现异常提醒
8.1 编译时期异常

import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class ExceptionDemo_01 {
public static void main(String[] args) throws ParseException {
// 1. 运行时异常
// int[] arr = {1, 2, 3, 4, 5};
// System.out.println(arr[10]);
// 2. 编译时异常 在编译期阶段就报错,必须处理,否则会报错
String date = "2021年1月5";
SimpleDateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日");
Date d = sdf.parse(date);
System.out.println(d);
}
}编译阶段: Java不会运行代码,只会检查语法是否错误,或者做一些性能的优化
语义区别
- 继承
Exception:表示该异常是检查型异常(Checked Exception)。这意味着在编译时,Java会强制要求程序员处理这个异常,要么通过try-catch捕获,要么通过throws声明抛出。- 适用于可以预见且需要程序显式处理的异常情况,例如文件不存在、网络连接失败等。
- 示例:
IOException、SQLException等。
- 继承
RuntimeException:表示该异常是非检查型异常(Unchecked Exception)。Java不会强制要求程序员处理这类异常。- 适用于程序逻辑错误或运行时错误,例如空指针异常、数组越界等。
- 示例:
NullPointerException、ArrayIndexOutOfBoundsException等。
判断依据
- 是否需要强制处理:
- 如果你希望调用者必须处理这个异常,那么应该继承
Exception。 - 如果你认为这个异常是程序逻辑错误,或者调用者无法合理恢复,那么应该继承
RuntimeException。
- 如果你希望调用者必须处理这个异常,那么应该继承
- 错误的性质:
- 外部环境问题(如文件不存在、网络错误)通常使用
Exception。 - 程序内部逻辑问题(如非法参数、空指针)通常使用
RuntimeException。
- 外部环境问题(如文件不存在、网络错误)通常使用
8.2 异常的作用
异常作用一: 异常是用来查询bug的关键参考信息
异常作用二: 异常可以作为方法内部的一种特殊返回值,以便通知调用者底层的执行情况
8.3 异常的处理方式
- JVM默认的处理方式:
- 把异常的名称,异常原因及异常出现的位置等信息输出在了控制台
- 程序停止执行下面的代码不会再执行了
- 自己处理
- 使用
try{} catch(){}语句
- 使用

抛出异常
throws- 写在方法定义处,表示声明一个异常告诉调用者,使用本方法可能会有哪些异常
- 编译时异常:必须要写。
- 运行时异常:可以不写。
throw- 写在方法内结束方法交给调用者手动抛出异常对象
- 方法中下面的代码不再执行了
public class ExceptionDemo_02 {
public static void main(String[] args) {
// 1. JVM默认的处理方式
/*
System.out.println("操作1");
System.out.println("操作2");
System.out.println(2/0); // ArithmeticException算数异常
System.out.println("操作4");
System.out.println("操作3");
*/
// 2. 自己捕获异常
/* try {
System.out.println("操作1");
System.out.println("操作2");
System.out.println(2/0); // 此处被捕获异常,try的内部不再继续执行,跳转到catch语句但是外部的代码继续执行
System.out.println("操作4");
} catch (ArithmeticException e) {
System.out.println("算数异常");
}
System.out.println("操作3");
*/
// 可以写多个catch语句捕获多个异常,假如多个异常中存在父子关系,父类一定要写在最下,否则根本走不到其他的异常,报错
/* int[] arr = {1, 2, 3, 4, 5};
try {
System.out.println("操作1");
System.out.println(arr[6]);
System.out.println("操作2");
System.out.println(2 / 0);
System.out.println("操作4");
} catch (ArithmeticException e) {
System.out.println("算数异常");
} catch (ArrayIndexOutOfBoundsException e) {
System.out.println("数组越界异常");
} catch
(Exception e) {
System.out.println("异常");
}
System.out.println("操作3");
*/
int[] arr = {1, 2, 3, 4, 5};
try {
System.out.println("操作");
} catch (ArithmeticException | ArrayIndexOutOfBoundsException e) { // 多个异常用 | 隔开
System.out.println("多个异常同种处理");
}
// 3. 抛出异常
// int [] arr2 = {1, 2, 3, 4, 5};
int[] arr2 = new int[0];
int max = 0;
try {
max = getMax(arr2);
} catch (Exception e) {
throw new RuntimeException(e);
}
System.out.println(max);
}
public static int getMax(int[] arr) /*throws NullPointerException, ArrayIndexOutOfBoundsException*/ {
if (arr == null) {
throw new NullPointerException("数组为空");
}
if (arr.length == 0) {
throw new ArrayIndexOutOfBoundsException("数组长度为0");
}
int max = arr[0];
for (int i = 1; i < arr.length; i++) {
max = max > arr[i] ? max : arr[i];
}
return max;
}
}8.4 throwable的成员方法
| 方法名称 | 说明 |
|---|---|
| public String getMessage() | 返回此 throwable 的详细消息字符串 |
| public String toString() | 返回此可抛出的简短描述 |
| public void printStackTrace() | 把异常的错误信息输出在控制台,不会停止执行 |
import java.util.Scanner;
public class ExceptIonDemo_03 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
Student st = new Student();
while (true){
try {
System.out.println("请输入学生的姓名");
String name = sc.nextLine();
st.setName(name);
System.out.println("请输入学生的年龄");
String ageStr = sc.nextLine();
int age = Integer.parseInt(ageStr);
st.setAge(age);
break;
}catch (NumberFormatException e){
System.out.println("年龄输入有误,请重新输入");
}catch (Exception e){
// e.printStackTrace();
System.out.println("年龄的范围或者名字长度超出限制");
}
}
}
}
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
if (name != null && name.length() >= 2 && name.length() <= 4) { // 注意此行
this.name = name;
} else {
throw new RuntimeException("姓名不合法");
}
}
public int getAge() {
return age;
}
public void setAge(int age) {
if (age >= 18 && age <= 50) { // 注意此行
this.age = age;
} else {
throw new RuntimeException("年龄不合法");
}
}
public String toString() {
return "Student{name = " + name + ", age = " + age + "}";
}
}
8.5 自定义异常
为了更确切地描述异常信息,自带的异常类已经不能满足我们的需求,(需要自定义异常类来准确描述程序运行过程中可能出现的特殊异常)
- 定义异常类
- 写继承关系
- 空参构造
- 带参构造
public class NameFormatException extends RuntimeException{
public NameFormatException() {
}
public NameFormatException(String message) {
super(message);
}
}9. 文件
9.1 File的常用方法
构造方法
| 方法名称 | 说明 |
|---|---|
| public File(String pathname) | 根据文件路径创建文件对象 |
| public File(String parent, String child) | 根据父路径名字符串和子路径名字符串创建文件对象 |
| public File(File parent, String child) | 根据父路径对应文件对象和子路径名字符串创建文件对象 |
File表示什么?
File对象表示路径,可以是文件、也可以是文件夹。这个路径可以是存在的,也可以是不存在的
绝对路径和相对路径是什么意思?
绝对路径是带盘符的,相对路径是不带盘符的,
默认到当前项目下去找。
import java.io.File;
public class FileDemo_01 {
public static void main(String[] args) {
// 1. 文件路径
File file = new File("D:/a.txt");
// 2. 根据父路径名字符串和子路径名字符串创建文件对象
File file1 = new File("D:/", "a.txt");
// 3. 根据父路径对应文件对象和子路径名字符串创建文件对象
File file2 = new File(new File("D:/"), "b.txt");
if (file.exists()) {
System.out.println("存在");
} else {
System.out.println("不存在");
}
}
}成员方法
判断和获取信息
| 方法名称 | 说明 |
|---|---|
| public boolean isDirectory() | 判断此路径名表示的File是否为文件夹 |
| public boolean isFile() | 判断此路径名表示的File是否为文件 |
| public boolean exists() | 判断此路径名表示的File是否存在 |
| public long length() | 返回文件的大小(字节数量) |
| public String getAbsolutePath() | 返回文件的绝对路径 |
| public String getPath() | 返回定义文件时使用的路径 |
| public String getName() | 返回文件的名称,带后缀 |
| public long lastModified() | 返回文件的最后修改时间(时间毫秒值) |
创建和删除
| 方法名称 | 说明 |
|---|---|
| public boolean createNewFile() | 创建一个新的空的文件,路径中没有后缀则创建没有后缀的文件 |
| public boolean mkdir() | 创建单级文件夹,aaa/ |
| public boolean mkdirs() | 创建多级文件夹,aaa/bbb/ccc |
| public boolean delete() | 删除文件、空文件夹,注意:彻底删除,不会经过回收站 |
获取并遍历
| 方法名称 | 说明 |
|---|---|
| public static File[] listRoots() | 列出可用的文件系统根 |
| public String[] list() | 获取当前该路径下所有内容 |
| public String[] list(FilenameFilter filter) | 利用文件名过滤器获取当前该路径下所有内容 |
| public File[] listFiles() | 获取当前该路径下所有内容 |
| public File[] listFiles(FileFilter filter) | 利用文件名过滤器获取当前该路径下所有内容 |
| public File[] listFiles(FilenameFilter filter) | 利用文件名过滤器获取当前该路径下所有内容 |
listFiles()方法:
- 当调用者File表示的路径不存在时或者是一个文件,
返回null - 当调用者File表示的路径是一个空文件夹时,
返回一个长度为0的数组 - 当调用者File表示的路径是一个有内容的文件夹时,
将里面所有文件和文件夹的路径放在File数组中返回(包括隐藏文件) - 当调用者File表示的路径是需要权限才能访问的文件夹时,
返回null
import java.io.File;
import java.io.FileFilter;
public class FileDemo_02 {
public static void main(String[] args) {
// 1. listRoots
File[] roots = File.listRoots();
for (File root : roots) {
// System.out.println(root);
}
// 2. list 仅能获取名字
File file = new File("D:/");
String[] list = file.list();
for (String s : list) {
// System.out.println(s);
}
// 3. list (FileFilter)
File file2 = new File("D:/");
// File[] files = file2.listFiles(new FileFilter() {
// @Override
// public boolean accept(File pathname) { // 依次表示文件夹里的每个文件或者文件夹
// return pathname.isFile() && pathname.getAbsolutePath().endsWith(".txt"); // 返回true表示保留,false表示不加入返回的数组
// }
// });
File[] files = file2.listFiles(pathname -> pathname.isFile() && pathname.getAbsolutePath().endsWith(".txt")); // 返回true表示保留,false表示不加入返回的数组
for (File f : files) {
System.out.println(f);
}
}
}import java.io.File;
import java.util.HashMap;
import java.util.Map;
public class 遍历并获取 {
public static void main(String[] args) {
File file = new File("C:\\Users\\86158\\Desktop\\aaa\\");
// boolean flag = removeDirRecursively(file);
// if (flag) {
// System.out.println("删除成功");
// } else {
// System.out.println("删除失败");
// File[] fileList = file.listFiles();
// if (fileList != null) {
// for (File f : fileList) {
// System.out.println(f.getName());
// }
// }
// }
//
countPrint(file);
for (Map.Entry<String, Integer> entry : hashMap.entrySet()) {
System.out.println(entry.getKey() + "\t" + entry.getValue());
}
long size = getAllSize(file);
System.out.println(size + "B");
}
/**
* 递归的删除一个文件的所有子文件
*
* @return {@code true} 删除成功
* @throws NullPointerException 如果 {@code file} 为 {@code null}
*/
public static boolean removeDirRecursively(File file) {
if (file == null) {
throw new NullPointerException("file must not be null");
}
if (file.isDirectory()) {
File[] fileList = file.listFiles();
if (fileList != null) {
for (File f : fileList) {
if (!removeDirRecursively(f)) {
return false;
}
}
}
}
return file.delete();
}
private static HashMap<String, Integer> hashMap = new HashMap<>();
public static void countPrint(File path) { // 统计文件类型,并打印输出
if (path == null) {
return;
}
if (path.isDirectory()) {
File[] childFiles = path.listFiles();
if (childFiles != null) {
for (File f : childFiles) {
countPrint(f);
}
}
} else {
String fileName = path.getName();
String[] suffixs = fileName.split("\\.");
String suffix;
if (suffixs.length == 0 || suffixs.length == 1) return; // 可能出现文件名没有后缀的情况
else {
suffix = suffixs[suffixs.length - 1]; // 获取文件后缀名,注意是最后的那个.的分割
}
if (hashMap.containsKey(suffix)) {
hashMap.put(suffix, hashMap.get(suffix) + 1);
} else {
hashMap.put(suffix, 1);
}
}
}
public static long getAllSize(File src) {
if (src == null) {
return 0;
}
long size = 0;
if (src.isDirectory()) {
File[] childFiles = src.listFiles();
if (childFiles != null) {
for (File f : childFiles) {
size += getAllSize(f);
}
}
} else {
size = src.length();
}
return size;
}
}10. IO流
读:内存读取文件中的数据(Input)
写:内存将数据写入文件(Output)

10.1 文件字节流
FileOutputStream:操作本地文件的字节输出流,可以把程序中的数据写到本地文件中。
- 构造方法的参数可以是文件路径,也可以是一个File文件对象,参数二是是否追加的boolean形参
- 如果目标文件不存在,会创建一个新的文件,但是要保证父级路径是存在的。如果目标文件存在,会覆盖
- 写入文件的是
字节数据,会被编码成ASCII字符,例如wirte(97)打开显示字母a,假如你想看到文件中的内容是97,需要将9和7分开写入对应的ASCII编码
| 方法名称 | 说明 |
|---|---|
| void write(int b) | 一次写一个字节数据 |
| void write(byte[] b) | 一次写一个字节数组数据 |
| void write(byte[] b, int off, int len) | 一次写一个字节数组的部分数据 |
FileInputStream
- 目标文件不存在,
直接报错 read()方法一次读一个字节,读出来的是数据在ASCII上对应的数字,读到文件末尾了,read方法返回-1。- 注意:read()方法每调用一次会移动一次指针
- 使用完必须释放资源,否则会产生资源泄漏。
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class 文件字节流 {
public static void main(String[] args) {
try {
// 参数1:文件路径,参数2:是否追加模式,默认不追加
FileOutputStream fos = new FileOutputStream("IOStream\\a.txt", false); // 相对路径是相对当前项目根目录
fos.write('a');
byte[] bytes = {98, 99, 100, 101}; //bcde
fos.write(bytes);
byte[] efgh = {101, 102, 103, 104};
fos.write(efgh, 1, 2); // 从bytes数组中索引为1开始,长度为2写入
// 写入换行符: Windows \r\n Linux \n Mac \r
fos.write("\r\nhelloWorld".getBytes());
fos.close();
// FileInputStream
FileInputStream fis = new FileInputStream("IOStream\\a.txt");
int num = fis.read(); // 一次读取一个字节,返回一个int类型(数据在ASCII码的对应码值),-1表示读取完毕
System.out.println(num); // 97
// 循环读取
while ((num = fis.read()) != -1) {
System.out.print((char) num);
}
fis.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
注意:第三次读取的时候,只读到了一个字节e,写入字节数组中覆盖c,所以第三次打印出来是ed,此时len=1
10.2 文件拷贝
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class 文件拷贝 {
public static void main(String[] args) throws IOException {
FileOutputStream fos = new FileOutputStream("IOStream//b.txt");
FileInputStream fis = new FileInputStream("IOStream//a.txt");
// 1. 一次读取一个字节,操作速度慢
int len;
// while ((len = fis.read()) != -1){
// fos.write(len);
// }
// 2. 一次读取一个字节数组,操作速度快
byte[] bytes = new byte[1024];
while ((len = fis.read(bytes))!= -1){
fos.write(bytes,0,len); // len表示本次读取的字节数,从bytes数组的0索引开始,写入len个字节,防止读取到上次的缓存数据
}
fos.close();
}
}try...catch异常处理
try {
FileOutputStream fos = new FileOutputStream("a.txt");
fos.write(97);
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 被finally控制的语句一定会执行,除非JVM退出AutoCloseable接口

import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class 自动关闭流 {
public static void main(String[] args) throws FileNotFoundException {
// JDK7 的写法,FileInputStream 和 FileOutputStream 都实现了 AutoCloseable 接口,所以可以自动关闭流
// try (FileOutputStream fos = new FileOutputStream("IOStream//b.txt");
// FileInputStream fis = new FileInputStream("IOStream//a.txt");) {
// int len;
// byte[] bytes = new byte[1024];
// while ((len = fis.read(bytes)) != -1) {
// fos.write(bytes, 0, len);
// }
// } catch (IOException e) {
// e.printStackTrace();
// }
// JDK9
FileOutputStream fos = new FileOutputStream("IOStream//b.txt");
FileInputStream fis = new FileInputStream("IOStream//a.txt");
try (fos; fis) {
int len;
byte[] bytes = new byte[1024];
while ((len = fis.read(bytes)) != -1) {
fos.write(bytes, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}10.3 字符集
计算机中用二进制来存储数据,一个二进制位叫bit,8比特位组成一个字节。
ASCII码表
一共有128种字符,对应不同的码值,从0到127,一个字节最多能表示2^8 = 256种数据。所以一个字节就足以表示所有ASCII码值。例如ASCII码表中字母a的码值是97(十进制)。转成二进制就是
GB2312字符集: 1980年发布,1981年5月1日实施的简体中文汉字编码国家标准。收录7445个图形字符,其中包括6763个简体汉字
BIG5字符集: 台湾地区繁体中文标准字符集,共收录13053个中文字,1984年实施
GBK字符集: 2000年3月17日发布,收录21003个汉字。 包含国家标准GB13000-1中的全部中日韩汉字,和BIG5编码中的所有汉字。
- 一个汉字用两个字节记录
- 高位字节二进制一定以1开头,转成十进制之后是一个负数,这样就能区分中文字符和英文字符
Unicode字符集: 国际标准字符集,它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息转换。
- UTF-16编码规则:用2~4个字节保存
- UTF-32编码规则:固定使用四个字节保存
UTF-8编码规则:用1~4个字节保存,中文使用三个字节,英文使用一个字节

Java中编码的方法
| String类中的方法 | 说明 |
|---|---|
public byte[] getBytes() |
使用默认方式进行编码 |
public byte[] getBytes(String charsetName) |
使用指定方式进行编码 |
Java中解码的方法
| String类中的方法 | 说明 |
|---|---|
String(byte[] bytes) |
使用默认方式进行解码 |
String(byte[] bytes, String charsetName) |
使用指定方式进行解码 |
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
public class 自定义编码 {
public static void main(String[] args) {
String str = "你好";
byte[] bytes = str.getBytes(StandardCharsets.UTF_8);
System.out.println(Arrays.toString(bytes));
String str1 = new String(bytes, StandardCharsets.UTF_8);
System.out.println(str1); // 编码和解码方式一致
String str2 = new String(bytes, StandardCharsets.ISO_8859_1);
System.out.println(str2); // 编码和解码方式不一致, 乱码
}
}10.4 字符流
字符流的底层就是字节流,但是加上了字符集的设定,根据不同的字符集调整每次读入字节数
| 构造方法 | 说明 |
|---|---|
public FileReader(File file) |
创建字符输入流关联本地文件 |
public FileReader(String pathname) |
创建字符输入流关联本地文件 |
| 成员方法 | 说明 |
|---|---|
public int read() |
读取数据,读到末尾返回-1 |
public int read(char[] buffer) |
读取多个数据,读到末尾返回-1 |
细节1: 按字节进行读取,遇到中文,一次读多个字节,读取后解码,返回一个整数
细节2: 读到文件末尾了,read方法返回-1。
import java.io.FileReader;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
public class 字符流 {
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("IOStream//a.txt", StandardCharsets.UTF_8);
int c;
// read()函数将读取到的二进制字节转为对应的十进制数据
// 如 a 的 二进制是 01100001,则 read()函数会将01100001 转成Unicode编码0x61 (00000000 0110 0001) 返回然后经过 int 类型转换成十进制97
while ((c = fr.read()) != -1){
// System.out.print((char)c);
System.out.println(c + " ");
}
fr.close();
// read(char[] b)
FileReader fr2 = new FileReader("IOStream//a.txt", StandardCharsets.UTF_8);
char[] chars = new char[2];
int len;
while ((len = fr2.read(chars)) != -1){
System.out.print(new String (chars, 0, len));
}
fr2.close();
}
}
char类型与Unicode
- Java的
char类型是一个16位无符号整数,范围从0x0000到0xFFFF,它直接对应于Unicode编码中的一个字符。- Unicode编码是一个标准,定义了每个字符的唯一编号。例如,“中”的Unicode编码是
0x4E2D。字符流与字节流的区别
- 字符流(如
FileReader)处理的是字符数据,它会自动根据指定的字符集(如 UTF-8、GBK 等)将字节解码为字符。- 字节流(如
FileInputStream)处理的是原始字节数据,不会自动进行字符编码的解码。
FileReader的构造方法
- 在你的代码中,
FileReader fr = new FileReader("IOStream//a.txt", StandardCharsets.UTF_8);使用了StandardCharsets.UTF_8指定了文件的编码格式为 UTF-8。- 当你调用
fr.read()方法时,FileReader会根据指定的 UTF-8 编码将读取到的字节解码为对应的 Unicode 编码值。强制类型转换
(char)
- 当你执行
(char)c时,实际上是将read()返回的整数(即字符的 Unicode 编码值)转换为char类型。- 这个转换过程是基于 Unicode 编码的,不需要额外指定编码格式,因为
char类型本身就是用来表示 Unicode 字符的。
| 构造方法 | 说明 |
|---|---|
public FileWriter(File file) |
创建字符输出流关联本地文件 |
public FileWriter(String pathname) |
创建字符输出流关联本地文件,清空文件若存在 |
public FileWriter(File file, boolean append) |
创建字符输出流关联本地文件,续写 |
public FileWriter(String pathname, boolean append) |
创建字符输出流关联本地文件,续写 |
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class 字符输出流 {
public static void main(String[] args) throws IOException {
FileWriter fw = new FileWriter("IOStream//b.txt");
// '我'的UTF-8编码对应的十进制是25105
fw.write(25105);
fw.write("你好");
char [] chars = {'a', 'b', 'c', '我'};
fw.write(chars);
fw.close();
}
}
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class FileReader缓冲区 {
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("IOStream//a.txt");
fr.read(); // 先将8192个字节读入缓冲区,再从缓冲区中读取一个字符
FileWriter fw = new FileWriter("IOStream//a.txt"); // 创建会清空文件
int c;
while ((c = fr.read()) != -1) { // 那么这里还能读取到数据吗?
System.out.println((char) c); // 可以,因为缓冲区没有被清空
}
fr.close();
fw.close();
}
}字符输出流
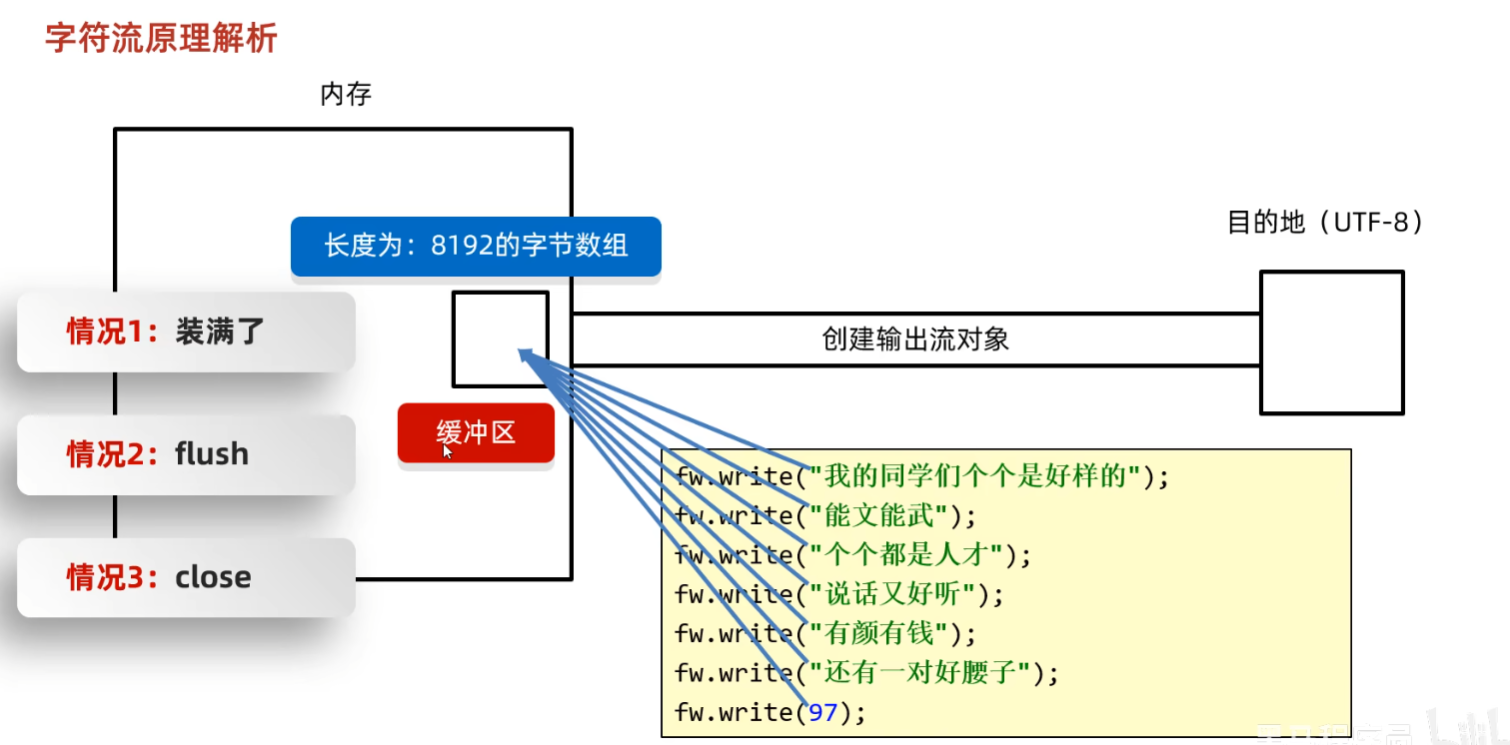
flush()和close()方法的区别
| 成员方法 | 说明 |
|---|---|
public void flush() |
将缓冲区中的数据,刷新到本地文件中,刷新完还能继续写入 |
public void close() |
释放资源/关流,断开通道 |
10.5 缓冲流
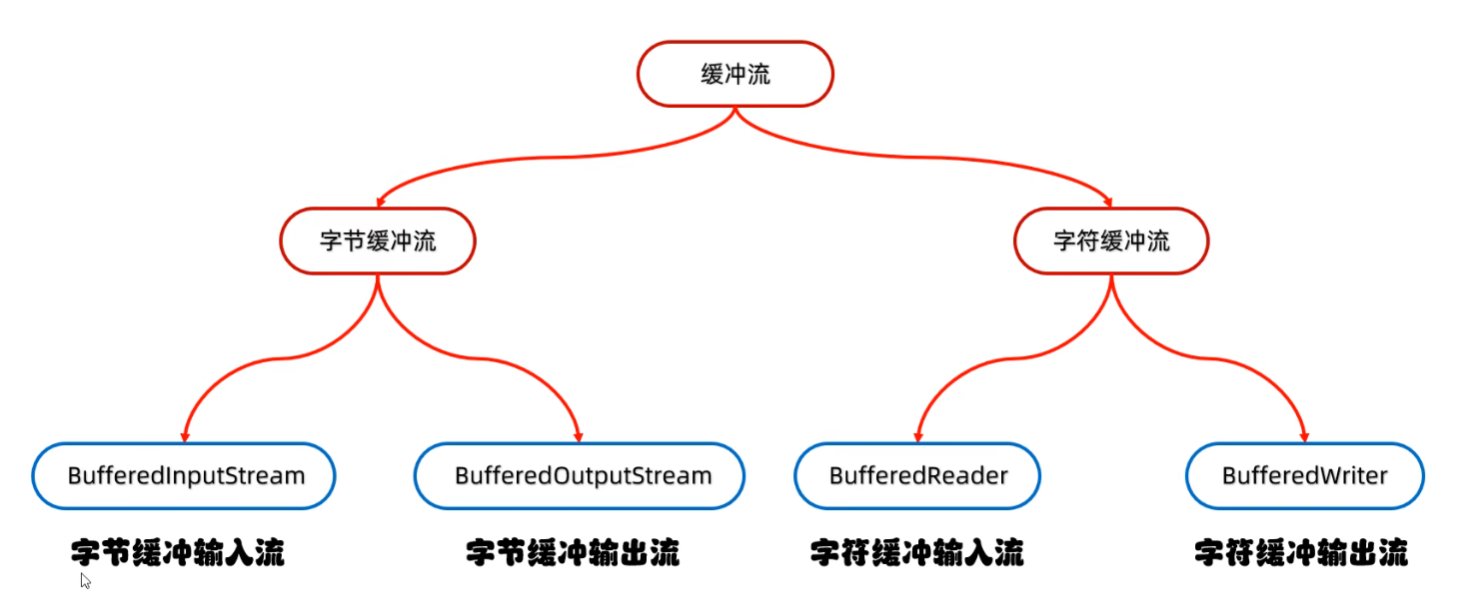
原理:底层自带了长度为8192的缓冲区提高性能
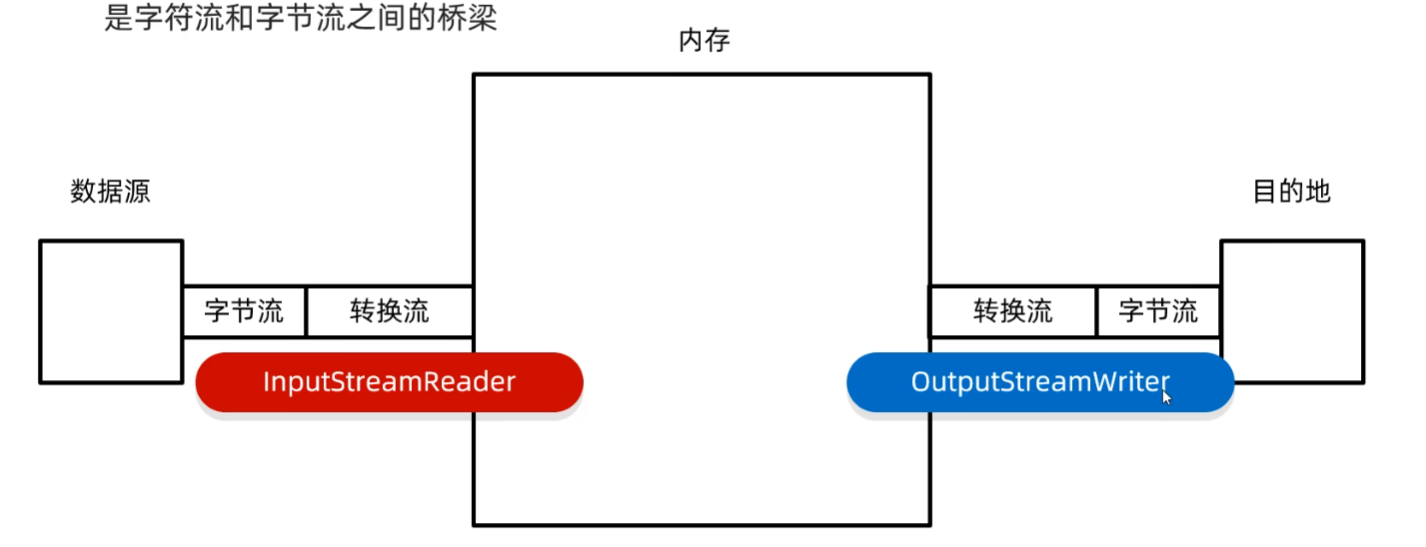
10.6 转换流
转换流是字符流和字节流之间的桥梁
package 转换流;
import java.io.*;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
public class 转换流Demo1 {
public static void main(String[] args) throws IOException {
/*
* 利用转换流按照指定字符编码读取
* */
//1.创建对象并指定字符编码
InputStreamReader isr = new InputStreamReader(new FileInputStream("IOStream//gbkfile.txt"),"GBK" );
// 2. 读取数据
int ch;
while ((ch = isr.read()) != -1){
System.out.println((char)ch);
}
// 3. 关闭资源
isr.close();
/* 第二种替代方案 推荐 */
FileReader fr = new FileReader("IOStream//gbkfile.txt", Charset.forName("GBK"));
int ch;
while ((ch = fr.read()) != -1){
System.out.print((char)ch);
}
fr.close();
}
}package 转换流;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.charset.Charset;
public class 练习 {
public static void main(String[] args) throws IOException {
//利用字节流读取文件中的数据,每次读一整行,而且不能出现乱码
// 1.字节流在读取中文的时候,是会出现乱码的,但是字符流可以搞定
// 2.字节流里面是没有读一整行的方法的,只有字符缓冲流才能搞定
FileInputStream fis = new FileInputStream("IOStream//a.txt");
InputStreamReader isr = new InputStreamReader(fis, Charset.forName("UTF-8"));
BufferedReader br = new BufferedReader(isr);
String line = null;
while ((line = br.readLine()) != null){
System.out.println(line);
}
br.close();
}
}10.7 序列化流/对象操作输出流
序列化流:将Java中的对象写入到本地文件中
| 构造方法 | 说明 |
|---|---|
| public ObjectOutputStream(OutputStream out) | 把基本流包装成高级流 |
| 成员方法 | 说明 |
|---|---|
public final void writeObject(Object obj) |
把对象序列化(写出)到文件中去 |
使用对象输出流将对象保存到文件时会出现NotserializableException异常,此时需要让JavaBean类实现Serializable接口
package 序列化;
import java.io.Serializable;
// 实现Serializable标记型接口,没有抽象方法需要实现
// 标记为接口就表明该对象能被序列化
public class Student implements Serializable {
private int age;
private String name;
public Student() {
}
public Student(int age, String name) {
this.age = age;
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String toString() {
return "Student{age = " + age + ", name = " + name + "}";
}
}反序列化流:可以把序列化到本地文件中的对象,读取到程序中来
| 构造方法 | 说明 |
|---|---|
public ObjectInputStream(InputStream out) |
把基本流变成高级流 |
| 成员方法 | 说明 |
|---|---|
public Object readObject() |
把序列化到本地文件中的对象,读取到程序中来 |
package 序列化;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
public class ObjInputStreamDemo01 {
public static void main(String[] args) throws IOException, ClassNotFoundException {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("IOStream\\src\\序列化\\student.txt"));
Object o = ois.readObject();
// 强转成对应类型
Student stu1 = (Student) o;
System.out.println(stu1.getName());
System.out.println(stu1.getAge());
System.out.println(o);
ois.close();
}
}每个实现Serializable的类Java内部都会维护一个long类型的标识号,每次新增成员等会对类结构产生影响的操作都会修改版本号,当写入和读取时不是一个版本就会报错

所以需要自定义版本号
对IDEA进行设置使其
自动生成serialVersionUID,或高亮提示
- 设置中搜索Serializable
- 勾选
Serializable class without "serialVersionUlD"- 勾选
Transient field is not initialized on deserializatior中文版的勾选
transient字段在反序列化时未初始化和JVM语言下的不带'serialVersionUlD' 的可序列化类
序列化的两个小知识点:
- 每个实现序列化接口的内部都应维护一个
private static final long serialVersionUID字段用于标识当前类版本 - 类的字段可以使用
transient关键字修饰,该字段被序列化时不会写入文件中,可以保护字段信息
多个自定义对象的序列化
package 序列化;
import java.io.*;
import java.util.ArrayList;
public class 多个对象序列化 {
public static void main(String[] args) throws IOException, ClassNotFoundException {
writeStudent();
readStudent();
}
public static void writeStudent() throws IOException {
Student stu1 = new Student(18,"张三");
Student stu2 = new Student(19,"李四");
Student stu3 = new Student(20,"王五");
ArrayList<Student> list = new ArrayList<>();
list.add(stu1);
list.add(stu2);
list.add(stu3);
// 序列化的时候使用ArrayList包装集合,这样可以一次序列化多个对象
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("IOStream\\src\\序列化\\students.txt"));
oos.writeObject(list);
oos.close();
}
public static void readStudent() throws IOException, ClassNotFoundException {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("IOStream\\src\\序列化\\students.txt"));
ArrayList<Student> list = (ArrayList<Student>)ois.readObject();
for (Student stu : list) {
System.out.println(stu);
}
ois.close();
}
}10.8 打印流
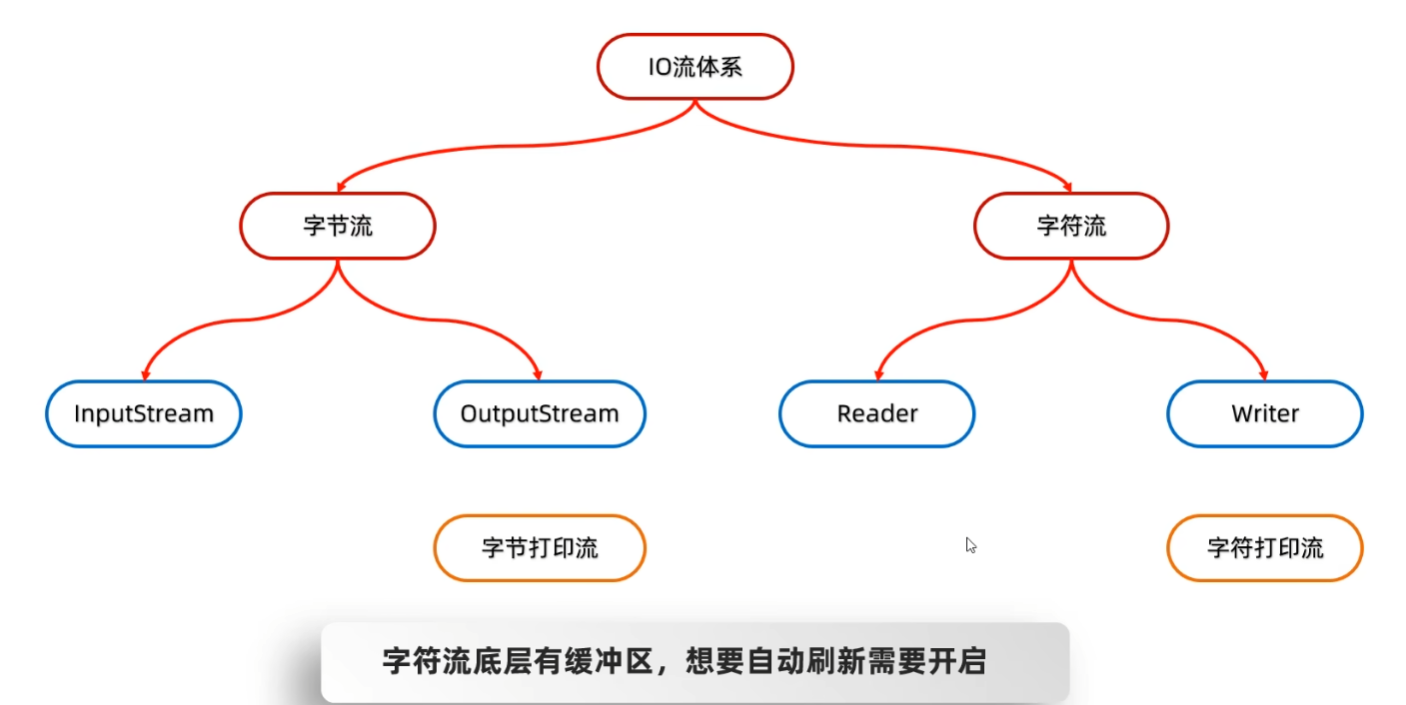
分类: 打印流一般是指:打印流,打印机两个类
特点:
打印流只操作文件目的地,不操作数据源
特有的写出方法可以实现,数据原样写出
例如: 打印:97 文件中:97 打印:true 文件中:true
特有的写出方法,可以实现自动刷新,自动换行
打印一次数据 = 写出+换行+刷新
字节打印流
| 构造方法 | 说明 |
|---|---|
public PrintStream(OutputStream/File/String) |
关联字节输出流/文件/文件路径 |
public PrintStream(String fileName, Charset charset) |
指定字符编码 |
public PrintStream(OutputStream out, boolean autoFlush) |
自动刷新 |
public PrintStream(OutputStream out, boolean autoFlush, String encoding) |
指定字符编码且自动刷新 |
| 成员方法 | 说明 |
|---|---|
public void write(int b) |
常规方法:规则跟之前一样,将指定的字节写出 |
public void println(Xxx xx) |
特有方法:打印任意数据,自动刷新,自动换行 |
public void print(Xxx xx) |
特有方法:打印任意数据,不换行 |
public void printf(String format, Object... args) |
特有方法:带有占位符的打印语句,不换行 |
public class PrintStreamDemo01 {
public static void main(String[] args) throws IOException {
PrintStream ps = new PrintStream(new FileOutputStream("IOStream//src//打印流//a.txt"), true, StandardCharsets.UTF_8);
// 写出数据
ps.println("你好"); // 写出+自动刷新+换行
ps.print(97);
ps.printf("%s爱上了%s", "阿珍", "阿强");
// 关闭流
ps.close();
}
}字符打印流
构造方法和成员方法于字节打印流类似
PrintWriter pw = new PrintWriter(new FileWriter("IOStream//src//打印流//a.txt"),true);
pw.print("hello");
pw.close();10.9 格式化输出(补充)
| 占位符 | 说明 | 示例 |
|---|---|---|
%s |
字符串 | System.out.printf("%s", "Hello"); 输出:Hello |
%d |
十进制整数 | System.out.printf("%d", 123); 输出:123 |
%f |
浮点数 | System.out.printf("%f", 123.456); 输出:123.456000 |
%.2f |
浮点数,保留两位小数 | System.out.printf("%.2f", 123.456); 输出:123.46 |
%b |
布尔值 | System.out.printf("%b", true); 输出:true |
%c |
字符 | System.out.printf("%c", 'A'); 输出:A |
%x 或 %X |
十六进制整数 | System.out.printf("%x", 255); 输出:ff |
%o |
八进制整数 | System.out.printf("%o", 255); 输出:377 |
%e 或 %E |
科学计数法表示的浮点数 | System.out.printf("%e", 123.456); 输出:1.234560E+02 |
%a 或 %A |
十六进制浮点数 | System.out.printf("%a", 123.456); 输出:0x1.efc66p+02 |
%tH:%tM:%tS |
时间(小时:分钟:秒) | System.out.printf("%tH:%tM:%tS", Instant.now()); 输出:当前时间 |
%n |
平台相关的换行符 | System.out.printf("%n"); 输出:换行 |
%% |
打印百分号 | System.out.printf("%%"); 输出:% |
10.10 解压缩流
压缩包中的每一个文件都是一个ZipEntry对象
解压本质:把每一个ZipEntry对象按照层级拷贝到本地的另一个文件夹中
package 压缩包流;
import java.io.*;
import java.util.zip.ZipEntry;
import java.util.zip.ZipInputStream;
public class ZipStream {
public static void unzip(InputStream inputStream, File dest) throws IOException {
// 确保目标目录存在
if (!dest.exists()) {
boolean mkdirs = dest.mkdirs();
if (!mkdirs) {
throw new IOException("无法创建目标目录: " + dest.getAbsolutePath());
}
}
try (ZipInputStream zis = new ZipInputStream(inputStream)) {
ZipEntry entry;
while ((entry = zis.getNextEntry()) != null) {
System.out.println("正在处理: " + entry.getName());
File file = new File(dest, entry.getName());
if (entry.isDirectory()) {
// 如果是目录,则创建目录
boolean mkdirs = file.mkdirs();
if (!mkdirs) {
System.out.println("警告: 未能创建目录: " + file.getAbsolutePath());
}
} else {
// 如果是文件,则写入文件内容
File parentDir = file.getParentFile();
if (!parentDir.exists()) {
boolean mkdirs = parentDir.mkdirs();
if (!mkdirs) {
throw new IOException("无法创建父目录: " + parentDir.getAbsolutePath());
}
}
try (FileOutputStream fos = new FileOutputStream(file)) {
byte[] buffer = new byte[1024];
int len;
while ((len = zis.read(buffer)) != -1) {
fos.write(buffer, 0, len);
}
}
}
// 关闭当前条目
zis.closeEntry();
}
}
}
public static void main(String[] args) {
String zipFilePath = "IOStream\\src\\压缩包流\\test.zip";
String destPath = "IOStream\\src\\压缩包流\\test";
try (FileInputStream fis = new FileInputStream(zipFilePath)) {
File destDir = new File(destPath);
unzip(fis, destDir);
System.out.println("解压完成!");
} catch (IOException e) {
e.printStackTrace();
}
}
} 压缩文件夹
package 压缩包流;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.zip.ZipEntry;
import java.util.zip.ZipOutputStream;
public class ZipStreamDemo02 {
public static void main(String[] args) {
String sourceFolder = "IOStream\\src\\压缩包流\\test"; // 需要压缩的文件夹路径
String zipFile = "IOStream\\src\\压缩包流\\a.zip"; // 输出的 ZIP 文件路径
try (FileOutputStream fos = new FileOutputStream(zipFile);
ZipOutputStream zos = new ZipOutputStream(fos)) {
File folderToZip = new File(sourceFolder);
addFolderToZip(folderToZip, folderToZip.getName(), zos);
System.out.println("文件夹已成功压缩到 " + zipFile);
} catch (IOException e) {
e.printStackTrace();
}
}
private static void addFolderToZip(File folder, String baseName, ZipOutputStream zos) throws IOException {
File[] files = folder.listFiles();
if (files != null) {
for (File file : files) {
if (file.isDirectory()) {
addFolderToZip(file, baseName + "/" + file.getName(), zos);
continue;
}
FileInputStream fis = new FileInputStream(file);
ZipEntry zipEntry = new ZipEntry(baseName + "/" + file.getName());
zos.putNextEntry(zipEntry);
byte[] bytes = new byte[1024];
int length;
while ((length = fis.read(bytes)) >= 0) {
zos.write(bytes, 0, length);
}
fis.close();
}
}
}
}10.11 Commons.io
Commons-io是apache开源基金组织提供的一组有关IO操作的开源工具包
作用: 提高IO流的开发效率
导入jar包
常用的类和方法
| FileUtils类(文件/文件夹相关) | 说明 |
|---|---|
static void copyFile(File srcFile, File destFile) |
复制文件 |
static void copyDirectory(File srcDir, File destDir) |
复制文件夹(复制文件夹内容) |
static void copyDirectoryToDirectory(File srcDir, File destDir) |
复制文件夹(源文件夹整个复制到目的) |
static void deleteDirectory(File directory) |
删除文件夹 |
static void cleanDirectory(File directory) |
清空文件夹(文件夹本身还在) |
static String readFileToString(File file, Charset encoding) |
读取文件中的数据变成字符串 |
static void write(File file, CharSequence data, String encoding) |
写出数据 |
| IOUtils类(流相关相关) | 说明 |
|---|---|
public static int copy(InputStream input, OutputStream output) |
复制文件 |
public static int copyLarge(Reader input, Writer output) |
复制大文件 |
public static String readLines(Reader input) |
读取数据 |
public static void write(String data, OutputStream output) |
写出数据 |
package CommonsIO库;
import org.apache.commons.io.FileUtils;
import java.io.File;
import java.io.IOException;
public class CommonsIODemo {
public static void main(String[] args) throws IOException {
FileUtils.copyFile(new File("IOStream\\a.txt"),new File("IOStream\\b.txt"));
// copyDirectory是直接将文件夹的内容复制到对应文件夹
FileUtils.copyDirectory(new File("IOStream\\dira"),new File("IOStream\\dirb"));
// copyDirectoryToDirectory会使drib//dira存在文件夹
FileUtils.copyDirectoryToDirectory(new File("IOStream\\dira"),new File("IOStream\\dirb"));
}
}10.12 Hutool工具包
package Hutool包的使用;
import cn.hutool.core.io.FileUtil;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
public class HutoolDemo01 {
public static void main(String[] args) {
try {
// 使用正斜杠替代反斜杠,避免路径分隔符问题
File file = FileUtil.file("D:/Develop software/code/javaCode/JavaProject/IOStream/src/Hutool包的使用/a.txt");
System.out.println("目标文件路径: " + file);
// 如果文件已存在,则先删除
if (file.exists()) {
file.delete();
}
// 创建文件
File touch = FileUtil.touch(file);
System.out.println("创建的文件: " + touch);
// 写入内容到文件
List<String> linesToWrite = new ArrayList<>();
linesToWrite.add("aaa");
linesToWrite.add("aaa");
linesToWrite.add("aaa");
File file3 = FileUtil.appendLines(linesToWrite, "p:/a.txt", "UTF-8");
System.out.println("写入内容的文件: " + file3);
// 读取文件内容
List<String> linesRead = FileUtil.readLines("D:/a.txt", "UTF-8");
System.out.println("读取的文件内容: " + linesRead);
} catch (Exception e) {
// 捕获并打印异常信息
System.err.println("文件操作失败: " + e.getMessage());
e.printStackTrace();
}
}
}11. 网络爬虫
package 练习;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.sql.SQLOutput;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.stream.Collectors;
public class 网络爬虫 {
public static void main(String[] args) throws IOException {
String familyNameUrl = "https://hanyu.baidu.com/shici/detail?pid=0b2f26d4c0ddb3ee693fdb1137ee1b0d&from=kg0";
String boyNameUrl = "http://www.haoming8.cn/baobao/10881.html";
String girlNameUrl = "http://www.haoming8.cn/baobao/7641.html";
// 爬取数据
String familyUrlContent = MyWebCrawler(familyNameUrl);
String boyUrlContent = MyWebCrawler(boyNameUrl);
String girlUrlContent = MyWebCrawler(girlNameUrl);
// 正则解析数据
ArrayList<String> familyNameTempList = parseData(familyUrlContent, "([^a-z]{4})(,|。)", 1);
ArrayList<String> boyNameTempList = parseData(boyUrlContent, "([\\u4E00-\\u9FA5]{2})(、|。)", 1);
ArrayList<String> girlNameTempList = parseData(girlUrlContent, "(.. ){4}..", 0);
ArrayList<String> familyNameList = new ArrayList<>();
for (String s : familyNameTempList) {
for (int i = 0; i < s.length(); i++) {
familyNameList.add(String.valueOf(s.charAt(i)));
}
}
ArrayList<String> boyNameList = new ArrayList<>();
for (String s : boyNameTempList){
if (!boyNameList.contains(s)){
boyNameList.add(s);
}
}
ArrayList<String> girlNameList = new ArrayList<>();
System.out.println(girlNameTempList);
for (String str : girlNameTempList) {
String list[] = str.split(" ");
girlNameList.addAll(Arrays.asList(list));
}
System.out.println(girlNameList);
}
private static ArrayList<String> parseData(String str, String regex, int index) { // 正则解析数据, index 代表第几个分组
ArrayList<String> list = new ArrayList<>();
// 创建正则表达式对象
Pattern pattern = Pattern.compile(regex);
// 匹配数据
Matcher matcher = pattern.matcher(str);
while (matcher.find()) {
String group = matcher.group(index); // index 代表第几个分组,0表示全部,在正则中,一个括号包裹的是一组
list.add(group);
// System.out.println(group);
}
return list;
}
private static String MyWebCrawler(String Url) throws IOException {
// 1. 定义StringBuilder拼接数据
StringBuilder stringBuilder = new StringBuilder();
// 2. URL类
URL url = new URL(Url);
// 3. 打开输入流
URLConnection urlConnection = url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(), "utf-8"); // 处理中文字符
int ch;
while ((ch = inputStreamReader.read()) != -1) {
stringBuilder.append((char) ch);
}
// 4. 关闭输入流
inputStreamReader.close();
// System.out.println(stringBuilder.toString());
return stringBuilder.toString();
}
}12. properties配置文件
- 后缀名是
.properties - 每一行都是键值对
Java为了方便读写properties类型配置文件,写好了一个Properties类
properties是一个双列集合集合,拥有Map集合所有的特点。
有一些特有的方法,可以把集合中的数据,按照键值对的形式写到配置文件当中,也可以把配置文件中的数据,读取到集合中来。
package Properties类;
import java.io.*;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
import java.util.HashMap;
import java.util.Properties;
import java.util.Set;
import java.util.Map;
public class ProperitesDemo {
public static void main(String[] args) throws IOException {
Properties properties = new Properties();
// 添加数据
// 虽然setProperty方法的形参是Object类型能添加任意类型,但实际上一般只添加字符串类型
properties.setProperty("name", "张三");
properties.setProperty("age", "18");
properties.setProperty("sex", "男");
Set<Object> keys = properties.keySet();
for (Object key : keys) {
String value = properties.getProperty(key.toString());
System.out.println(key + "=" + value);
}
Set<Map.Entry<Object, Object>> entries = properties.entrySet();
for (Map.Entry<Object, Object> entry : entries) {
System.out.println(entry.getKey() + "=" + entry.getValue());
}
FileWriter fw = new FileWriter(new File("IOStream\\src\\Properties类\\properties.txt"), StandardCharsets.UTF_8);
// 写入文件
try {
properties.store(fw, "注释");
} catch (Exception e) {
e.printStackTrace();
}
fw.close();
// 读取文件
try {
Properties properties1 = new Properties();
properties1.load(new java.io.FileInputStream("IOStream\\src\\Properties类\\properties.txt"));
} catch (Exception e) {
e.printStackTrace();
}
for (Object key : properties.keySet()){
System.out.println(key + "=" + properties.getProperty(key.toString()));
}
}
}12. 多线程
12.1 进程和线程
进程:CPU调度和分配资源的基本单位,它拥有自己的地址空间、内存、数据栈、以及其他系统资源
线程:比进程更小的能独立运行的单位,一个进程可以包含多个线程,它们共享进程的地址空间和其他资源。
12.2 多线程的应用场景

12.3 并发和并行
并发:有多个指令在单个CPU上交替执行
并行:在同一时刻,有多个CPU核心执行多个指令
12.4 多线程实现方式
- MyThread类继承Thread类重写run方法
- MyRunnable类继承Runnable接口并重写run方法,在使用Thread(new MyRunnable()).start方法
public class ThreadDemo01 {
public static void main(String[] args) {
MyThread myThread1 = new MyThread("线程1");
MyThread myThread2 = new MyThread("线程2");
myThread1.start();
myThread2.start();
}
static class MyThread extends Thread{
public MyThread(String threadName){
setName(threadName);
}
public void run(){
for (int i = 0; i < 10; i++)
System.out.println(getName() + "线程执行");
}
}
}public class ThreadDemo02 {
public static void main(String[] args) {
Thread thread1 = new Thread(new MyRunnable());
Thread thread2 = new Thread(new MyRunnable());
thread1.setName("线程1");
thread2.setName("线程2");
thread1.start();
thread2.start();
}
public static class MyRunnable implements Runnable{
@Override
public void run() {
for (int i = 0; i < 10; i++)
System.out.println(Thread.currentThread().getName() + "线程执行");
}
}
}- 继承Callable对象和实现Future接口,特点是能够获取到
多线程运行的结果
import java.util.concurrent.Callable;
import java.util.concurrent.FutureTask;
public class ThreadDemo03 {
public static void main(String[] args) {
MyCallable myCallable = new MyCallable();
FutureTask<Integer> futureTask = new FutureTask<>(myCallable);
Thread thread = new Thread(futureTask);
thread.start();
try {
Integer sum = futureTask.get(); // 通过get方法获取线程的返回值
System.out.println(sum); // 5050
} catch (Exception e) {
e.printStackTrace();
}
}
public static class MyCallable implements Callable<Integer> {
// 泛型:返回值类型
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 0; i <= 100; i++){
sum += i;
}
return sum;
}
}
}12.5 常见的成员方法
| 方法名称 | 说明 |
|---|---|
| String getName() | 返回此线程的名称 |
| void setName(String name) | 设置线程的名字(构造方法也可以设置名字) |
static Thread currentThread() |
获取当前线程的对象 |
static void sleep(long time) |
让线程休眠指定的时间,单位为毫秒 |
| setPriority(int newPriority) | 设置线程的优先级 |
| final int getPriority() | 获取线程的优先级 |
| final void setDaemon(boolean on) | 设置为守护线程 |
public static void yield() |
出让线程/出让cpu控制权 |
| public void join() | 插入线程/抢夺cpu控制权 |
- 如果没有设置线程名字,默认的名字格式是
Thread-序号,序号从0开始 - 当JVM虚拟机启动之后,会自动的启动多条线程,其中有一条线程就叫做main线程,他的作用就是去调用main方法,并执行里面的代码在以前,我们写的所有的代码,其实都是运行在main线程当中
- Java采取的是抢占式线程策略,
线程默认的优先级是5
守护线程的特点
- 生命周期依赖于用户线程 :守护线程的生命周期依赖于用户线程,只有当所有用户线程都结束时,守护线程才会被强制终止。
- 优先级较低 :守护线程通常具有较低的优先级,以确保用户线程能够优先获得 CPU 时间。
- 执行可能不完整 :由于守护线程的生命周期依赖于用户线程,如果用户线程突然终止,守护线程可能无法完成其任务,因此守护线程的执行可能是不完整的。
- 不会影响程序退出 :即使守护线程仍在运行,只要所有非守护线程都执行完毕,程序也会正常退出,不会等待守护线程结束。
public class MethodsUse {
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(()->{
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName()+"-->"+i);
}
},"线程1");
t1.start();
System.out.println(t1.getPriority());
Thread t2 = new Thread(()->{
for (int i = 0; i < 10; i++){
System.out.println(Thread.currentThread().getName() + "-->" + i);
}
},"用户线程");
Thread t3 = new Thread(()->{
for (int i = 0; i < 100; i++){
System.out.println(Thread.currentThread().getName() + "-->" + i);
}
},"守护线程");
// 用户线程结束后,即使守护线程还没有完成任务,也会退出
t3.setDaemon(true);
t2.start();
t3.start();
Thread.yield();
Thread t4 = new Thread(()->{
for (int i = 0; i < 100; i++){
System.out.println(Thread.currentThread().getName() + "-->" + i);
}
},"join线程");
t4.start();
// join 方法,让当前(主)线程等待,直到join线程执行完,主线程才继续执行
t4.join();
for (int i = 0; i < 100; i++){
System.out.println(Thread.currentThread().getName()+ "主线程" + "-->" + i);
}
}
}12.6 线程的生命周期
12.7 线程的安全问题
对共享数据的读写,在多线程情况下,一定是会出现问题的
解决办法
- 同步代码块
synchronized(锁){
操作共享数据的代码
}- 同步方法: 直接把
synchronized关键字加在方法名前
在 Java 中,synchronized 关键字用于实现线程同步,它会在特定条件下自动获取和释放锁。具体到你的 Producer.java 文件中的代码,我们来分析一下锁的获取和释放时机。
- 锁的获取
在你的代码中,锁的获取发生在 synchronized (BufferList.lock) 语句处:
synchronized (BufferList.lock) {
// 需要同步的代码块
}- 获取锁:当线程执行到
synchronized (BufferList.lock)时,会尝试获取BufferList.lock这个对象的锁。 - 等待获取锁:如果该锁已经被其他线程持有,当前线程会进入等待状态,直到锁被释放。
- 锁的释放
锁的释放有以下几种情况:
2.1 正常执行完 synchronized 代码块
synchronized (BufferList.lock) {
// 需要同步的代码块
// ...
} // 在这里释放锁- 释放锁:当线程执行完
synchronized代码块中的所有代码并退出该代码块时,会自动释放持有的锁。 - 其他线程有机会获取锁:锁释放后,其他等待该锁的线程有机会获取锁并继续执行。
2.2 在 synchronized 代码块中抛出异常
synchronized (BufferList.lock) {
// 需要同步的代码块
throw new SomeException(); // 抛出异常
} // 在这里释放锁- 释放锁:如果在
synchronized代码块中抛出了异常并且没有被捕获,锁也会被自动释放。 - 异常传播:异常会向外层传播,锁的释放不会影响异常的传播。
2.3 在 synchronized 代码块中调用 wait() 方法
synchronized (BufferList.lock) {
if (someCondition) {
BufferList.lock.wait(); // 调用 wait() 方法
}
} // 锁在这里不会立即释放,而是等到 wait() 返回- 释放锁:当线程在
synchronized代码块中调用Object.wait()方法时,会释放持有的锁,并进入等待状态。 - 重新获取锁:当
wait()方法返回(通常是因为其他线程调用了notify()或notifyAll()方法)时,线程会重新尝试获取锁。获取锁成功后,继续执行wait()之后的代码。
- 具体到你的代码
在你的 Producer.java 代码中,锁的释放情况如下:
synchronized (BufferList.lock) {
if (BufferList.list.size() < BufferList.maxSize) {
System.out.println("生产者" + Thread.currentThread().getName() + "正在生产" + i++ + "碗");
BufferList.list.add(i);
BufferList.lock.notifyAll(); // 唤醒所有等待的线程,消费者线程可以继续消费
} else if (BufferList.list.size() == BufferList.maxSize) {
try {
BufferList.lock.wait(); // wait方法绑定当前线程的锁,使当前线程等待
break; // 碗已满,等待消费者消费
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
} // 在这里释放锁(正常执行完代码块或抛出异常)- 正常执行完代码块:如果条件满足(
BufferList.list.size() < BufferList.maxSize),生产者线程会执行生产操作并唤醒所有等待的线程,然后退出synchronized代码块,此时锁会被释放。 - 调用
wait()方法:如果条件不满足(BufferList.list.size() == BufferList.maxSize),生产者线程会调用BufferList.lock.wait(),此时锁会被释放,线程进入等待状态。当wait()方法返回(被唤醒)并重新获取锁后,如果遇到break语句,会退出while循环并最终退出synchronized代码块,锁会被释放。
12.8 Lock锁对象
Lock 接口是 java.util.concurrent.locks 包中的核心接口之一,用于提供比 synchronized 更灵活的线程同步机制,经常使用的实现类有:
ReentrantLock()- ReentrantReadWriteLock()
- StampedLock()
import java.util.concurrent.locks.ReentrantLock;
public class Lock {
static int tickets = 100;
static ReentrantLock lock = new ReentrantLock();
public static void main(String[] args) {
Runnable task = () -> {
while (true) {
lock.lock();
try {
if (tickets <= 0) break;
int currentTicket = tickets--;
System.out.println(Thread.currentThread().getName() + "卖出了第" + currentTicket + "张票");
} finally {
lock.unlock();
}
try {
Thread.sleep(100); // 移出锁外休眠
} catch (InterruptedException e) {
Thread.currentThread().interrupt(); // 恢复中断状态
break;
}
}
};
new Thread(task, "窗口1").start();
new Thread(task, "窗口2").start();
}
}12.9 死锁
死锁是多线程中常见的资源竞争问题,死锁有四个条件:
互斥条件:资源是独占的且排他使用,进程互斥使用资源,即任意时刻一个资源只能给一个进程使用,其他进程若申请一个资源,而该资源被另z进程占有时,则申请者等待直到资源被占有者释放。不可剥夺条件:进程所获得的资源在未使用完毕之前,不被其他进程强行剥夺,而只能由获得该资源的进程资源释放。请求和保持条件:进程每次申请它所需要的一部分资源,在申请新的资源的同时,继续占用已分配到的资源。循环等待条件:在发生死锁时必然存在一个进程等待队列{P1,P2,…,Pn},其中P1等待P2占有的资源,P2等待P3占有的资源,Pn等待P1占有的资源,形成一个进程等待环路,环路中每一个进程所占有的资源同时被另一个申请,也就是前一个进程占有后一个进程所申请地资源。
12.10 生产者和消费者
| 方法名称 | 说明 |
|---|---|
| void wait() | 当前线程等待,直到被其他线程唤醒 |
| void notify() | 随机唤醒单个线程 |
| void notifyAll() | 唤醒所有线程 |
package 生产者和消费者;
public class Producer extends Thread {
private int count; // 每个生产者线程自己的计数变量
@Override
public void run() {
while (true) {
synchronized (BufferList.lock) {
// 这里用if或者while都可以
if (BufferList.list.size() >= BufferList.maxSize) {
try {
System.out.println("缓冲区满,生产者" + Thread.currentThread().getName() + "等待");
BufferList.lock.wait();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
System.out.println("生产者" + Thread.currentThread().getName() + "正在生产" + (++count) + "碗");
BufferList.list.add(count);
BufferList.lock.notifyAll();
}
}
}
}package 生产者和消费者;
public class Consumer extends Thread {
@Override
public void run() {
while (true) {
synchronized (BufferList.lock) {
// 这里用if或者while都可以
if (BufferList.list.size() == 0) {
try {
System.out.println("缓冲区空,消费者" + Thread.currentThread().getName() + "等待");
BufferList.lock.wait();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
System.out.println("消费者" + Thread.currentThread().getName() + "正在消费" + BufferList.list.get(0) + "碗");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
BufferList.list.remove(0);
BufferList.lock.notifyAll();
}
}
}
}package 生产者和消费者;
import java.util.ArrayList;
public class BufferList {
public static ArrayList<Integer> list = new ArrayList<>();
public static int maxSize = 3;
public static final Object lock = new Object();
}
12.11 基于阻塞队列的

12.12 线程的状态


12.13 线程池
| 任务拒绝策略 | 说明 |
|---|---|
| ThreadPoolExecutor.AbortPolicy | 默认策略: 丢弃任务并抛出RejectedExecutionException异常 |
| ThreadPoolExecutor.DiscardPolicy | 丢弃任务,但是不抛出异常 这是不推荐的做法 |
| ThreadPoolExecutor.DiscardOldestPolicy | 抛弃队列中等待最久的任务 然后把当前任务加入队列中 |
| ThreadPoolExecutor.CallerRunsPolicy | 调用任务的run()方法绕过线程池直接执行 |
线程池定义多大合适?

package 线程池;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class 自定义线程池 {
public static void main(String[] args) {
// ThreadPoolExecutor是线程池的实现类
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
2, // 核心线程数
5, // 最大线程数,不能为0,且要求大于核心线程数
2, // 空闲线程存活时间
TimeUnit.SECONDS, // 时间单位
new ArrayBlockingQueue<>(3), // 阻塞任务队列
Executors.defaultThreadFactory(), // 创建线程工厂
new ThreadPoolExecutor.DiscardOldestPolicy() // 线程拒绝策略
);
}
}13. 反射
反射允许对封装类的字段,方法和构造函数的信息进行编程访问

13.1 获取class对象
class对象就是字节码文件,只要获取到class对象后,就能获取到类的信息,获取到class对象的方式有三种
- Class.forName(“全类名”);
- 类名.class
- 对象.getClass();
package 获取class对象的三种方式;
public class Demo {
public static void main(String[] args) throws ClassNotFoundException {
// 获取字节码的三种方式
// 1. Class.forName(全类名) 全类名就是 包名 + 类名
Class<?> clazz = Class.forName("获取class对象的三种方式.Student");
// 2. 类名.class
Class<?> clazz2 = Student.class;
// 3. 对象.getClass()
Student s = new Student();
Class<?> clazz3 = s.getClass();
System.out.println((clazz == clazz2)? clazz2 == clazz3 : "false");
}
}13.2 通过class获取构造方法
| 方法 | 说明 |
|---|---|
Constructor<?>[] getConstructors() |
返回所有公共构造方法对象的数组 |
Constructor<?>[] getDeclaredConstructors() |
返回所有构造方法对象的数组 |
Constructor<T> getConstructor(Class<?>... parameterTypes) |
返回单个公共构造方法对象 |
Constructor<T> getDeclaredConstructor(Class<?>... parameterTypes) |
返回单个构造方法对象 |
package 获取class对象的三种方式;
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationTargetException;
import java.util.Arrays;
public class 获取构造方法 {
public static void main(String[] args) throws NoSuchMethodException, InvocationTargetException, InstantiationException, IllegalAccessException {
// 1. 构造方法其实也是一个对象
Class<?> clazz = Student.class;
//获取公共权限的
Constructor<?>[] constructor1 = clazz.getConstructors();
for (Constructor<?> c : constructor1) {
System.out.println(c);
}
// 获取所有权限的
Constructor<?>[] constructor2 = clazz.getDeclaredConstructors();
for (Constructor<?> c : constructor2) {
System.out.println(c);
}
// 获取对应参数的构造方法
Constructor<?> constructor3 = clazz.getConstructor(String.class, int.class, int.class, String.class);
System.out.println(constructor3);
System.out.println(constructor3.getModifiers()); // public 修饰符public是用常量1代表, private修饰符是2, protected修饰符是4
System.out.println(Arrays.toString(constructor3.getParameters())); // 参数信息,可能idea就是这样实现代码提示功能的??
constructor3.setAccessible(true); // 暴力反射:设置临时取消权限
Student student =(Student) constructor3.newInstance("张三", 18, 100, "男");
System.out.println(student);
}
}
便于位运算操作
- 位掩码表示 :每个修饰符常量对应一个唯一的 2 的幂数,可以将其视为一个位掩码。例如,
public修饰符用 1(二进制为 0001)表示,private用 2(二进制为 0010)表示,protected用 4(二进制为 0100)表示,static用 8(二进制为 1000)表示等。当需要表示多个修饰符的组合时,可以通过按位或(|)操作将这些位掩码组合起来。如一个同时具有public和static修饰符的方法,其修饰符组合值为 1 | 8 = 9(二进制为 1001),这样可以用一个整数简洁地表示多个修饰符的组合情况。- 快速检查和判断 :在需要判断某个修饰符是否存在时,可以利用按位与(
&)操作。例如,要判断一个方法是否为public,只需将该方法的修饰符整数值与public对应的位掩码(1)进行按位与操作,若结果不为 0,则说明该方法具有public修饰符。这种检查方式非常高效,因为位运算是计算机硬件层面支持的基本操作之一,执行速度极快。节省内存空间
- 紧凑的存储 :相较于使用多个布尔值或其他方式来分别表示每个修饰符的存在与否,使用一个整数来存储修饰符组合可以大大节省内存空间。例如,如果有 10 个修饰符,使用 10 个布尔值需要 10 个字节(假设每个布尔值占 1 个字节),而使用一个 32 位的整数只需要 4 个字节就可以表示所有修饰符的组合情况,大大提高了内存的利用率。
提高运算效率
- 快速组合和拆分 :由于 2 的幂的特殊性质,在进行修饰符的组合和拆分操作时,可以利用位运算的特性快速完成。如前面提到的按位或操作用于组合修饰符,按位与操作用于拆分和判断修饰符,这些位运算操作在计算机内部的执行速度比其他复杂的运算(如加减乘除等)要快得多,从而提高了程序的运行效率。
符合计算机底层数据表示和处理方式
- 二进制友好 :计算机底层使用二进制来表示和处理数据,而 2 的幂在二进制中具有简洁且易于识别的形式。每个修饰符对应的位掩码在二进制中只有一个位为 1,其余位为 0,这使得在进行位运算时,计算机可以快速准确地确定各个修饰符的位位置和状态,符合计算机底层数据处理的逻辑和方式,有利于计算机硬件对数据的高效处理。
| 方法 | 说明 |
|---|---|
T newInstance(Object... initargs) |
根据指定的构造方法创建对象 |
setAccessible(boolean flag) |
设置为 true,表示取消访问检查 |
13.3 通过class获取字段
| 方法 | 说明 |
|---|---|
Field[] getFields() |
返回所有公共成员变量对象的数组 |
Field[] getDeclaredFields() |
返回所有成员变量对象的数组 |
Field getField(String name) |
返回单个公共成员变量对象 |
Field getDeclaredField(String name) |
返回单个成员变量对象 |
| 方法 | 说明 |
|---|---|
void set(Object obj, Object value) |
赋值 |
Object get(Object obj) |
获取值 |
package 获取class对象的三种方式;
import java.lang.reflect.Field;
import java.util.Arrays;
public class 获取字段 {
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException {
Class<?> clazz = Student.class;
Field [] fields = clazz.getFields();
System.out.println(Arrays.toString(fields)); // 获取所有公共权限的成员变量
Field [] fields1 = clazz.getDeclaredFields(); // 获取所有权限的成员变量
System.out.println(Arrays.toString(fields1));
Field field = clazz.getField("clazzName");
System.out.println(field);
System.out.println(field.getModifiers());
Student student = new Student("zhangsan",19,100,"男");
field.set(student,"学生");
System.out.println(clazz.getField("clazzName").get(student));
}
}13.4 通过class获取成员方法
Class类中用于获取成员方法的方法
| 方法名称 | 描述 |
|---|---|
Method[] getMethods() |
返回所有公共成员方法对象的数组,包括继承的方法 |
Method[] getDeclaredMethods() |
返回所有成员方法对象的数组,不包括继承的方法 |
Method getMethod(String name, Class<?>... parameterTypes) |
返回单个公共成员方法对象,参数包括方法名和参数类型 |
Method getDeclaredMethod(String name, Class<?>... parameterTypes) |
返回单个成员方法对象,参数包括方法名和参数类型 |
Method类中用于创建对象的方法
| 方法名称 | 描述 |
|---|---|
Object invoke(Object obj, Object... args) |
运行方法 参数一:用 obj对象调用该方法参数二:调用方法的传递的参数(如果没有就不写) 返回值:方法的返回值(如果没有就不写) |
package 获取class对象的三种方式;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
/**
* 反射获取类成员方法教学示例
* 演示内容:
* 1. 获取公共方法(含继承方法)
* 2. 获取类自身声明方法
* 3. 反射调用方法
* 4. 获取方法抛出的异常类型
*/
public class 获取成员方法 {
public static void main(String[] args) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
// 通过类字面量获取Class对象(假设Student类存在)
Class<?> clazz = Student.class;
// 示例1:获取所有公共方法(包括父类方法)
System.out.println("==== 公共方法(含继承方法) ====");
Method[] methods = clazz.getMethods();
for (Method m : methods) {
System.out.println("方法签名: " + m);
System.out.println(" 返回类型: " + m.getReturnType().getSimpleName());
}
// 示例2:获取类自身声明的所有方法(包括私有方法)
System.out.println("\n==== 类自身声明的方法 ====");
Method[] declaredMethods = clazz.getDeclaredMethods();
for (Method m : declaredMethods) {
System.out.println("方法签名: " + m);
System.out.println(" 修饰符: " + m.getModifiers());
}
// 示例3:反射调用方法
Student student = new Student("zangsan", 20, 100, "男");
System.out.println("\n==== 反射调用setName方法 ====");
Method method = clazz.getMethod("setName", String.class);
method.invoke(student, "张三"); // 相当于 student.setName("张三")
System.out.println("修改后对象: " + student);
// 示例4:获取方法抛出的异常类型
System.out.println("\n==== 方法异常类型 ====");
Class<?>[] exceptionTypes = method.getExceptionTypes();
if (exceptionTypes.length == 0) {
System.out.println("该方法未声明抛出检查型异常");
}
for (Class<?> exceptionType : exceptionTypes) {
System.out.println("异常类型: " + exceptionType.getName());
}
}
} 14. 动态代理
特点:无侵入式的给代码增加额外的功能
JDK动态代理
(流程图说明:用户调用代理对象方法 → 触发 InvocationHandler → 执行增强逻辑 → 反射调用真实对象方法)
// 1. 定义业务接口(代理的抽象层)
interface UserService {
void save(); // 被代理的核心方法
}
// 2. 真实对象实现(被代理的目标)
class UserServiceImpl implements UserService {
public void save() {
System.out.println("保存用户"); // 核心业务逻辑
}
}
// 3. 代理处理器(核心增强逻辑)
class LogHandler implements InvocationHandler {
private Object target; // 持有真实对象的引用
public LogHandler(Object target) { // 依赖注入真实对象
this.target = target;
}
// 方法拦截器(所有代理方法都会经过这里)
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
System.out.println("[日志] 调用方法:" + method.getName()); // 前置增强
Object result = method.invoke(target, args); // 反射调用真实方法(关键连接点)
// 此处可添加后置增强逻辑
return result;
}
}
// 4. 代理对象创建过程(运行时动态生成)
public class Main {
public static void main(String[] args) {
// 创建真实对象(被代理目标)
UserService service = new UserServiceImpl();
// 动态生成代理对象(关键三步)
UserService proxy = (UserService) Proxy.newProxyInstance(
service.getClass().getClassLoader(), // ① 使用目标类的类加载器
new Class[]{UserService.class}, // ② 代理类要实现的接口列表
new LogHandler(service) // ③ 处理器(包含增强逻辑)
);
// 通过代理对象调用方法(触发增强逻辑)
proxy.save();
}
}执行过程详解
代理对象创建阶段(ClassLoader 加载期间):
Proxy.newProxyInstance(...)- 动态生成代理类:JDK 在内存中生成名为
$Proxy0的类文件 - 类结构特征:
public final class $Proxy0 extends Proxy implements UserService { public final void save() { super.h.invoke(this, m3, null); // m3 是 Method 对象缓存 } }
- 动态生成代理类:JDK 在内存中生成名为
方法调用阶段(运行时):
proxy.save() → $Proxy0.save() → LogHandler.invoke()- 调用栈顺序:
- 用户调用
proxy.save() - 代理类调用
InvocationHandler.invoke() - 执行日志打印(前置增强)
- 反射调用
target.save()(真实方法) - 返回结果(可插入后置处理)
- 用户调用
- 调用栈顺序:
关键机制说明
| 机制 | 说明 |
|---|---|
| 类加载器选择 | 使用目标类的类加载器,保证代理类与目标类在同一个类空间 |
| 接口数组 | 确定代理类实现的接口,这也是 JDK 代理必须基于接口的原因 |
| 方法对象缓存 | Method 对象会被缓存(如示例中的 m3),避免重复反射获取 |
| 代理类实例化 | 通过 Proxy.newProxyInstance 返回的实例实际上是被动态生成的代理类实例 |
调试技巧
查看代理类(JDK 8+):
System.setProperty("jdk.proxy.ProxyGenerator.saveGeneratedFiles", "true");运行后会在项目根目录生成
$Proxy0.class文件验证代理类型:
System.out.println(proxy.getClass().getName()); // 输出 com.sun.proxy.$Proxy0 System.out.println(proxy instanceof Proxy); // 输出 true
典型应用场景
- AOP 实现:Spring 声明式事务管理
- RPC 框架:Dubbo 的消费者代理
- 日志监控:方法调用耗时统计
- 权限校验:在方法调用前进行权限验证
特别注意:如果目标对象没有实现任何接口,JDK 动态代理将无法使用,此时应选择 CGLIB 代理方案。




