
推荐系统经典模型 Wide & Deep 详解 (全网之最)_wide&deep-CSDN博客
【王喆-推荐系统】模型篇-(task5)wide&deep模型-阿里云开发者社区
(64 封私信) 一文读懂Embedding的概念,以及它和深度学习的关系 - 知乎
讲解论文 推荐系统经典模型 Wide & Deep 详解 (全网之最)_wide&deep-CSDN博客
过拟合(overfitting)和欠拟合(underfitting)出现原因及如何避免方案-CSDN博客
https://www.doubao.com/thread/w54c9f676fd231492
1.什么是Wide&Deep模型
Wide & Deep 模型是 Google 在 2016 年提出的一种结合了记忆和泛化的机器学习模型,它融合了 Wide(宽)模型和 Deep(深)模型的优势,主要用于处理结构化数据,在推荐系统、广告点击率预估等领域应用广泛。
- 模型结构
Wide 部分:- 主要是一个线性模型,它能够学习到记忆式的特征组合,例如在推荐系统中,可以记忆特定用户和特定物品之间的直接关联。这些特征组合通常是通过手工设计或者交叉特征的方式得到的。例如,将用户的年龄、性别与物品的类别组合成新的特征,像 “年龄在 20 - 30 岁的女性用户购买化妆品的次数” 这样的特征组合。
- Wide 模型通过逻辑回归(对于分类问题)或线性回归(对于回归问题)来拟合这些线性特征。它的优势在于可以很好地利用已有的知识,对于一些通过经验可以预知的特征组合能够很好地拟合,避免了复杂模型可能带来的过拟合问题。
Deep 部分:- 这部分是一个前馈神经网络,用于学习特征的复杂组合和非线性关系。它将原始特征进行嵌入(embedding),将高维、稀疏的特征转换为低维、稠密的向量表示。例如,对于用户的 ID、物品的类别等稀疏特征,通过嵌入操作可以将其映射到一个连续的向量空间。
- 然后,这些嵌入后的特征会通过多层神经网络进行处理,每一层神经网络的节点通过激活函数(如 ReLU)引入非线性,从而能够学习到数据中复杂的模式。例如,在广告点击率预估中,Deep 部分可以学习到用户的各种特征(如浏览历史、兴趣爱好等)与广告特征(如广告内容、投放位置等)之间的复杂交互关系。
- 联合训练
Wide & Deep 模型的 Wide 部分和 Deep 部分是联合训练的。它们共享相同的输入特征,然后通过一个联合损失函数(如分类问题中的对数损失函数、回归问题中的均方误差函数)进行训练。- 在训练过程中,Wide 部分的权重和 Deep 部分的神经网络参数会同时更新。这种联合训练的方式使得模型
既可以利用 Wide 模型的记忆能力,又能够发挥 Deep 模型的泛化能力,从而在处理既有明确特征关联又有复杂交互关系的数据时表现出色。
- 应用场景示例
- 推荐系统 :在
推荐商品或内容时,Wide 部分可以根据用户过去的行为记录(如购买历史、浏览记录等)中已知的特征组合(如用户经常购买某一品牌的商品)来做出快速的推荐判断。而 Deep 部分可以深入挖掘用户和物品的潜在特征,比如用户的潜在兴趣爱好可能并未直接体现在其历史记录中,但通过学习其他用户的相似行为和物品特征的复杂关系,可以发现并推荐更符合用户潜在兴趣的商品或内容。 - 广告点击率预估 :对于预测用户是否会点击某个广告,Wide 部分可以利用已经确定的用户特征(如用户的地理位置、设备类型等)与广告特征(如广告的类别、广告主的行业等)的简单组合来初步估计点击率。Deep 部分则可以捕捉到更深层次的用户意图和广告内容的匹配度等复杂因素,从而更精准地预估广告点击率。
- 推荐系统 :在
- 模型优势
- 结合记忆和泛化 :Wide 模型记忆已知的特征组合,能够很好地处理规则明确的部分;Deep 模型学习复杂的特征交互,能够发现潜在的模式,避免了单一模型可能存在的局限性,提高了模型的准确性和泛化能力。
- 适应多种业务场景 :在很多实际业务场景中,既有一些明确的业务规则可以利用(通过 Wide 模型),又存在许多复杂的用户行为和特征交互(通过 Deep 模型),Wide & Deep 模型能够很好地适应这些场景,为实际应用提供更有效的解决方案。
2.怎么基于MindSpore来实现
# Copyright 2020 Huawei Technologies Co., Ltd
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ============================================================================
"""wide and deep model"""
import numpy as np
from mindspore import nn, context
from mindspore import Parameter, ParameterTuple
import mindspore.common.dtype as mstype
from mindspore.ops import functional as F
from mindspore.ops import composite as C
from mindspore.ops import operations as P
from mindspore.nn import Dropout
from mindspore.nn.optim import Adam, FTRL, LazyAdam
from mindspore.common.initializer import Uniform, initializer
from mindspore.context import ParallelMode
from mindspore.nn.wrap.grad_reducer import DistributedGradReducer
from mindspore.communication.management import get_group_size
np_type = np.float32
ms_type = mstype.float32
def init_method(method, shape, name, max_val=1.0):
'''
parameter init method
'''
if method in ['uniform']:
params = Parameter(initializer(
Uniform(max_val), shape, ms_type), name=name)
elif method == "one":
params = Parameter(initializer("ones", shape, ms_type), name=name)
elif method == 'zero':
params = Parameter(initializer("zeros", shape, ms_type), name=name)
elif method == "normal":
params = Parameter(initializer("normal", shape, ms_type), name=name)
return params
def init_var_dict(init_args, in_vars):
'''
var init function
'''
var_map = {}
_, _max_val = init_args
for _, iterm in enumerate(in_vars):
key, shape, method = iterm
if key not in var_map.keys():
if method in ['random', 'uniform']:
var_map[key] = Parameter(initializer(
Uniform(_max_val), shape, ms_type), name=key)
elif method == "one":
var_map[key] = Parameter(initializer(
"ones", shape, ms_type), name=key)
elif method == "zero":
var_map[key] = Parameter(initializer(
"zeros", shape, ms_type), name=key)
elif method == 'normal':
var_map[key] = Parameter(initializer(
"normal", shape, ms_type), name=key)
return var_map
# 全连接层:每个神经元都和上一层全部输出相连接,然后加上偏置项
class DenseLayer(nn.Cell):
"""
Dense Layer for Deep Layer of WideDeep Model;
Containing: activation, matmul, bias_add;
Args:
"""
def __init__(self, input_dim, output_dim, weight_bias_init, act_str,
keep_prob=0.5, use_activation=True, convert_dtype=True, drop_out=False):
super(DenseLayer, self).__init__()
weight_init, bias_init = weight_bias_init
self.weight = init_method(
weight_init, [input_dim, output_dim], name="weight")
self.bias = init_method(bias_init, [output_dim], name="bias")
self.act_func = self._init_activation(act_str)
self.matmul = P.MatMul(transpose_b=False)
self.bias_add = P.BiasAdd()
self.cast = P.Cast()
self.dropout = Dropout(keep_prob=keep_prob)
self.use_activation = use_activation
self.convert_dtype = convert_dtype
self.drop_out = drop_out
# 设置激活函数
def _init_activation(self, act_str):
act_str = act_str.lower()
if act_str == "relu":
act_func = P.ReLU()
elif act_str == "sigmoid":
act_func = P.Sigmoid()
elif act_str == "tanh":
act_func = P.Tanh()
return act_func
def construct(self, x):
'''
Construct Dense layer
'''
if self.training and self.drop_out:
x = self.dropout(x)
if self.convert_dtype:
x = self.cast(x, mstype.float16)
weight = self.cast(self.weight, mstype.float16)
bias = self.cast(self.bias, mstype.float16)
wx = self.matmul(x, weight)
wx = self.bias_add(wx, bias)
if self.use_activation:
wx = self.act_func(wx)
wx = self.cast(wx, mstype.float32)
else:
wx = self.matmul(x, self.weight)
wx = self.bias_add(wx, self.bias)
if self.use_activation:
wx = self.act_func(wx)
return wx
class WideDeepModel(nn.Cell):
"""
From paper: " Wide & Deep Learning for Recommender Systems"
Args:
config (Class): The default config of Wide&Deep
"""
def __init__(self, config):
super(WideDeepModel, self).__init__()
self.batch_size = config.batch_size
host_device_mix = bool(config.host_device_mix)
parameter_server = bool(config.parameter_server)
parallel_mode = context.get_auto_parallel_context("parallel_mode")
is_auto_parallel = parallel_mode in (ParallelMode.SEMI_AUTO_PARALLEL, ParallelMode.AUTO_PARALLEL)
if is_auto_parallel:
self.batch_size = self.batch_size * get_group_size()
is_field_slice = config.field_slice
sparse = config.sparse
self.field_size = config.field_size
self.vocab_size = config.vocab_size
self.vocab_cache_size = config.vocab_cache_size
self.emb_dim = config.emb_dim
self.deep_layer_dims_list = config.deep_layer_dim
self.deep_layer_act = config.deep_layer_act
self.init_args = config.init_args
self.weight_init, self.bias_init = config.weight_bias_init
self.weight_bias_init = config.weight_bias_init
self.emb_init = config.emb_init
self.drop_out = config.dropout_flag
self.keep_prob = config.keep_prob
self.deep_input_dims = self.field_size * self.emb_dim
self.layer_dims = self.deep_layer_dims_list + [1]
self.all_dim_list = [self.deep_input_dims] + self.layer_dims
init_acts = [('Wide_b', [1], self.emb_init)]
var_map = init_var_dict(self.init_args, init_acts)
self.wide_b = var_map["Wide_b"]
self.dense_layer_1 = DenseLayer(self.all_dim_list[0],
self.all_dim_list[1],
self.weight_bias_init,
self.deep_layer_act,
convert_dtype=True, drop_out=config.dropout_flag)
self.dense_layer_2 = DenseLayer(self.all_dim_list[1],
self.all_dim_list[2],
self.weight_bias_init,
self.deep_layer_act,
convert_dtype=True, drop_out=config.dropout_flag)
self.dense_layer_3 = DenseLayer(self.all_dim_list[2],
self.all_dim_list[3],
self.weight_bias_init,
self.deep_layer_act,
convert_dtype=True, drop_out=config.dropout_flag)
self.dense_layer_4 = DenseLayer(self.all_dim_list[3],
self.all_dim_list[4],
self.weight_bias_init,
self.deep_layer_act,
convert_dtype=True, drop_out=config.dropout_flag)
self.dense_layer_5 = DenseLayer(self.all_dim_list[4],
self.all_dim_list[5],
self.weight_bias_init,
self.deep_layer_act,
use_activation=False, convert_dtype=True, drop_out=config.dropout_flag)
self.wide_mul = P.Mul()
self.deep_mul = P.Mul()
self.reduce_sum = P.ReduceSum(keep_dims=False)
self.reshape = P.Reshape()
self.deep_reshape = P.Reshape()
self.square = P.Square()
self.shape = P.Shape()
self.tile = P.Tile()
self.concat = P.Concat(axis=1)
self.cast = P.Cast()
self.unique = P.Unique().shard(((1,),))
self.wide_gatherv2 = P.Gather()
self.deep_gatherv2 = P.Gather()
if is_auto_parallel and sparse and not is_field_slice:
target = 'DEVICE'
if host_device_mix:
target = 'CPU'
self.wide_embeddinglookup = nn.EmbeddingLookup(self.vocab_size, 1, target=target,
slice_mode=nn.EmbeddingLookup.TABLE_ROW_SLICE)
if config.deep_table_slice_mode == "column_slice":
self.deep_embeddinglookup = nn.EmbeddingLookup(self.vocab_size, self.emb_dim, target=target,
slice_mode=nn.EmbeddingLookup.TABLE_COLUMN_SLICE)
self.dense_layer_1.dropout.dropout.shard(((1, get_group_size()),))
self.dense_layer_1.matmul.shard(((1, get_group_size()), (get_group_size(), 1)))
self.dense_layer_1.matmul.add_prim_attr("field_size", self.field_size)
self.deep_mul.shard(((1, 1, get_group_size()), (1, 1, 1)))
self.deep_reshape.add_prim_attr("skip_redistribution", True)
else:
self.deep_embeddinglookup = nn.EmbeddingLookup(self.vocab_size, self.emb_dim, target=target,
slice_mode=nn.EmbeddingLookup.TABLE_ROW_SLICE)
self.reduce_sum.add_prim_attr("cross_batch", True)
self.embedding_table = self.deep_embeddinglookup.embedding_table
elif is_auto_parallel and host_device_mix and is_field_slice and config.full_batch and config.manual_shape:
manual_shapes = tuple((s[0] for s in config.manual_shape))
self.deep_embeddinglookup = nn.EmbeddingLookup(self.vocab_size, self.emb_dim,
slice_mode=nn.EmbeddingLookup.FIELD_SLICE,
manual_shapes=manual_shapes)
self.wide_embeddinglookup = nn.EmbeddingLookup(self.vocab_size, 1,
slice_mode=nn.EmbeddingLookup.FIELD_SLICE,
manual_shapes=manual_shapes)
self.deep_mul.shard(((1, get_group_size(), 1), (1, get_group_size(), 1)))
self.wide_mul.shard(((1, get_group_size(), 1), (1, get_group_size(), 1)))
self.reduce_sum.shard(((1, get_group_size(), 1),))
self.dense_layer_1.dropout.dropout.shard(((1, get_group_size()),))
self.dense_layer_1.matmul.shard(((1, get_group_size()), (get_group_size(), 1)))
self.embedding_table = self.deep_embeddinglookup.embedding_table
elif parameter_server:
cache_enable = self.vocab_cache_size > 0
target = 'DEVICE' if cache_enable else 'CPU'
if not cache_enable:
sparse = True
if is_auto_parallel and config.full_batch and cache_enable:
self.deep_embeddinglookup = nn.EmbeddingLookup(self.vocab_size, self.emb_dim, target=target,
slice_mode=nn.EmbeddingLookup.TABLE_ROW_SLICE,
sparse=sparse, vocab_cache_size=self.vocab_cache_size)
self.wide_embeddinglookup = nn.EmbeddingLookup(self.vocab_size, 1, target=target,
slice_mode=nn.EmbeddingLookup.TABLE_ROW_SLICE,
sparse=sparse, vocab_cache_size=self.vocab_cache_size)
else:
self.deep_embeddinglookup = nn.EmbeddingLookup(self.vocab_size, self.emb_dim, target=target,
sparse=sparse, vocab_cache_size=self.vocab_cache_size)
self.wide_embeddinglookup = nn.EmbeddingLookup(self.vocab_size, 1, target=target, sparse=sparse,
vocab_cache_size=self.vocab_cache_size)
self.embedding_table = self.deep_embeddinglookup.embedding_table
self.deep_embeddinglookup.embedding_table.set_param_ps()
self.wide_embeddinglookup.embedding_table.set_param_ps()
else:
self.deep_embeddinglookup = nn.EmbeddingLookup(self.vocab_size, self.emb_dim,
target='DEVICE', sparse=sparse)
self.wide_embeddinglookup = nn.EmbeddingLookup(self.vocab_size, 1,
target='DEVICE', sparse=sparse)
self.embedding_table = self.deep_embeddinglookup.embedding_table
def construct(self, id_hldr, wt_hldr):
"""
Args:
id_hldr: batch ids;
wt_hldr: batch weights;
"""
# Wide layer
wide_id_weight = self.wide_embeddinglookup(id_hldr)
# Deep layer
deep_id_embs = self.deep_embeddinglookup(id_hldr)
"""wt_hldr作为权重掩码(mask = reshape(wt_hldr, (batch_size, field_size, 1))),过滤无效特征,提升稀疏数据下的训练效率,与论文中处理稀疏输入的思路一致。"""
mask = self.reshape(wt_hldr, (self.batch_size, self.field_size, 1))
# Wide layer
wx = self.wide_mul(wide_id_weight, mask)
"""通过 wide_embeddinglookup 获取特征的嵌入值,结合 mask 和 wide_b 偏置项,经过 reduce_sum 和 reshape 得到最终输出。形状 -> (batch_size, 1),表示每个样本的 Wide 部分预测值。"""
wide_out = self.reshape(self.reduce_sum(wx, 1) + self.wide_b, (-1, 1))
# Deep layer
vx = self.deep_mul(deep_id_embs, mask)
deep_in = self.deep_reshape(vx, (-1, self.field_size * self.emb_dim))
deep_in = self.dense_layer_1(deep_in)
deep_in = self.dense_layer_2(deep_in)
deep_in = self.dense_layer_3(deep_in)
deep_in = self.dense_layer_4(deep_in)
"""输入经过 5 个全连接层(dense_layer_1 至 dense_layer_5),每层包含激活函数和 Dropout(除最后一层)。"""
deep_out = self.dense_layer_5(deep_in)
# 在这里直接将Wide层和Deep层相加,默认是1:1
out = wide_out + deep_out
return out, self.embedding_table
class NetWithLossClass(nn.Cell):
""""
Provide WideDeep training loss through network.
Args:
network (Cell): The training network
config (Class): WideDeep config
"""
def __init__(self, network, config):
super(NetWithLossClass, self).__init__(auto_prefix=False)
host_device_mix = bool(config.host_device_mix)
parameter_server = bool(config.parameter_server)
sparse = config.sparse
parallel_mode = context.get_auto_parallel_context("parallel_mode")
is_auto_parallel = parallel_mode in (ParallelMode.SEMI_AUTO_PARALLEL, ParallelMode.AUTO_PARALLEL)
self.no_l2loss = (is_auto_parallel if (host_device_mix or config.field_slice)
else parameter_server)
if sparse:
self.no_l2loss = True
self.network = network
self.l2_coef = config.l2_coef
self.loss = P.SigmoidCrossEntropyWithLogits()
self.square = P.Square()
self.reduceMean_false = P.ReduceMean(keep_dims=False)
if is_auto_parallel:
self.reduceMean_false.add_prim_attr("cross_batch", True)
self.reduceSum_false = P.ReduceSum(keep_dims=False)
def construct(self, batch_ids, batch_wts, label):
'''
Construct NetWithLossClass
'''
predict, embedding_table = self.network(batch_ids, batch_wts)
log_loss = self.loss(predict, label)
wide_loss = self.reduceMean_false(log_loss)
if self.no_l2loss:
deep_loss = wide_loss
else:
l2_loss_v = self.reduceSum_false(self.square(embedding_table)) / 2
deep_loss = self.reduceMean_false(log_loss) + self.l2_coef * l2_loss_v
return wide_loss, deep_loss
class IthOutputCell(nn.Cell):
def __init__(self, network, output_index):
super(IthOutputCell, self).__init__()
self.network = network
self.output_index = output_index
def construct(self, x1, x2, x3):
predict = self.network(x1, x2, x3)[self.output_index]
return predict
class TrainStepWrap(nn.Cell):
"""
Encapsulation class of WideDeep network training.
Append Adam and FTRL optimizers to the training network after that construct
function can be called to create the backward graph.
Args:
network (Cell): The training network. Note that loss function should have been added.
sens (Number): The adjust parameter. Default: 1024.0
host_device_mix (Bool): Whether run in host and device mix mode. Default: False
parameter_server (Bool): Whether run in parameter server mode. Default: False
"""
def __init__(self, network, sens=1024.0, host_device_mix=False, parameter_server=False,
sparse=False, cache_enable=False):
super(TrainStepWrap, self).__init__()
parallel_mode = context.get_auto_parallel_context("parallel_mode")
is_auto_parallel = parallel_mode in (ParallelMode.SEMI_AUTO_PARALLEL, ParallelMode.AUTO_PARALLEL)
self.network = network
self.network.set_train()
self.trainable_params = network.trainable_params()
weights_w = []
weights_d = []
for params in self.trainable_params:
if 'wide' in params.name:
weights_w.append(params)
else:
weights_d.append(params)
self.weights_w = ParameterTuple(weights_w)
self.weights_d = ParameterTuple(weights_d)
if (sparse and is_auto_parallel) or (parameter_server and not cache_enable):
self.optimizer_d = LazyAdam(
self.weights_d, learning_rate=3.5e-4, eps=1e-8, loss_scale=sens)
self.optimizer_w = FTRL(learning_rate=5e-2, params=self.weights_w,
l1=1e-8, l2=1e-8, initial_accum=1.0, loss_scale=sens)
if host_device_mix or parameter_server:
self.optimizer_w.target = "CPU"
self.optimizer_d.target = "CPU"
else:
self.optimizer_d = Adam(
self.weights_d, learning_rate=3.5e-4, eps=1e-8, loss_scale=sens)
self.optimizer_w = FTRL(learning_rate=5e-2, params=self.weights_w,
l1=1e-8, l2=1e-8, initial_accum=1.0, loss_scale=sens)
self.hyper_map = C.HyperMap()
self.grad_w = C.GradOperation(get_by_list=True,
sens_param=True)
self.grad_d = C.GradOperation(get_by_list=True,
sens_param=True)
self.sens = sens
self.loss_net_w = IthOutputCell(network, output_index=0)
self.loss_net_d = IthOutputCell(network, output_index=1)
self.loss_net_w.set_grad()
self.loss_net_d.set_grad()
self.reducer_flag = False
self.grad_reducer_w = None
self.grad_reducer_d = None
self.reducer_flag = parallel_mode in (ParallelMode.DATA_PARALLEL,
ParallelMode.HYBRID_PARALLEL)
if self.reducer_flag:
mean = context.get_auto_parallel_context("gradients_mean")
degree = context.get_auto_parallel_context("device_num")
self.grad_reducer_w = DistributedGradReducer(self.optimizer_w.parameters, mean, degree)
self.grad_reducer_d = DistributedGradReducer(self.optimizer_d.parameters, mean, degree)
def construct(self, batch_ids, batch_wts, label):
'''
Construct wide and deep model
'''
weights_w = self.weights_w
weights_d = self.weights_d
loss_w, loss_d = self.network(batch_ids, batch_wts, label)
sens_w = P.Fill()(P.DType()(loss_w), P.Shape()(loss_w), self.sens)
sens_d = P.Fill()(P.DType()(loss_d), P.Shape()(loss_d), self.sens)
grads_w = self.grad_w(self.loss_net_w, weights_w)(batch_ids, batch_wts,
label, sens_w)
grads_d = self.grad_d(self.loss_net_d, weights_d)(batch_ids, batch_wts,
label, sens_d)
if self.reducer_flag:
grads_w = self.grad_reducer_w(grads_w)
grads_d = self.grad_reducer_d(grads_d)
return F.depend(loss_w, self.optimizer_w(grads_w)), F.depend(loss_d,
self.optimizer_d(grads_d))
class PredictWithSigmoid(nn.Cell):
"""
Predict definition
"""
def __init__(self, network):
super(PredictWithSigmoid, self).__init__()
self.network = network
self.sigmoid = P.Sigmoid()
parallel_mode = context.get_auto_parallel_context("parallel_mode")
full_batch = context.get_auto_parallel_context("full_batch")
is_auto_parallel = parallel_mode in (ParallelMode.SEMI_AUTO_PARALLEL, ParallelMode.AUTO_PARALLEL)
if is_auto_parallel and full_batch:
self.sigmoid.shard(((1, 1),))
def construct(self, batch_ids, batch_wts, labels):
logits, _, = self.network(batch_ids, batch_wts)
pred_probs = self.sigmoid(logits)
return logits, pred_probs, labels3.背景:推荐系统
推荐系统(RS)主要是指应用协同智能(collaborative intelligence)做推荐的技术。推荐系统的两大主流类型是基于内容的推荐系统和协同过滤(Collaborative Filtering)。另外还有基于知识的推荐系统(包括基于本体和基于案例的推荐系统)是一类特殊的推荐系统,这类系统更加注重知识表征和推理。
推荐系统流程
推荐系统的一个典型场景是广告点击率预估。在我们浏览手机的应用商店时,经常可以看到商店会给我们推荐某些应用,某些推荐的应用往往是广告主通过付费来进行推广。
为了提高广告投放的准确度,广告点击率预估模型需要评价用户点击某些应用的概率,将用户最可能点击的应用进行推送,达到准确的投放广告的目的。一旦我们点击了其中的一个应用,商店就可以成功的向广告投放商进行收费,而广告主们也达到了应用推广的目的。美国著名的电影和电视节目提供商Netflix曾经发起了奖金为百万美元的推荐系统比赛,旨在提升推荐系统的准确度。在广告点击率预估的场景,性能提高了1%的模型往往可以为公司带来巨大的收入。
以APP商店中的推荐系统为例,其整体流程可以如下图所示:
- 给定一个查询,这个查询可能是用户相关的特征,推荐系统首先会从数据库中检索到查询相关的APP,由于APP的数量非常巨大,因此我们可以取最相关的100个检索结果作为候选APP,这一过程通常叫作
粗排。 - 然后将候选的100个APP送入排序模型中,此处的排序模型就是我们下面将要介绍的
Wide&Deep模型,这一过程也被叫作精排。 - 排序完成后,我们可以将点击概率最高的APP放置于用户最容易注意到的地方。无论用户是否点击了我们的推荐结果,我们都可以构造一个新的日志文件。在累积了一定数量的日志文件后,就可以继续微调排序模型,提高模型的准确程度。

Wide部分
Wide部分是一个线性网络,即y = w*x。
其设计目的是为了记住数据中特定的特征组合方式。例如广告点击率的场景,购买了电脑主机的用户,点击显示器,键盘等物件广告的概率特别高。因此可以将用户最近是否购买了电脑作为输入模型的输入,也就是特征。假设当前Wide网络只有一个特征,当该特征取1时,y = w*x可以得到y=0.9(假设w的值是0.9),当该特征取0时,y=0。y输出值越大,会增大模型对应用户点击概率的估计。
回到上述APP应用推荐的场景中,可以看到下面图2-1模型结构的Cross Product Transformation,就是我们的wide部分的输入。Cross Product Transformation是指特征交叉,即将User Installed App和Impression APP进行组合。例如用户手机已经安装了微信,且当前的待估计的APP为QQ,那么这个**组合特征就是(User Installed App=’微信’, Impression APP=’QQ’)**。
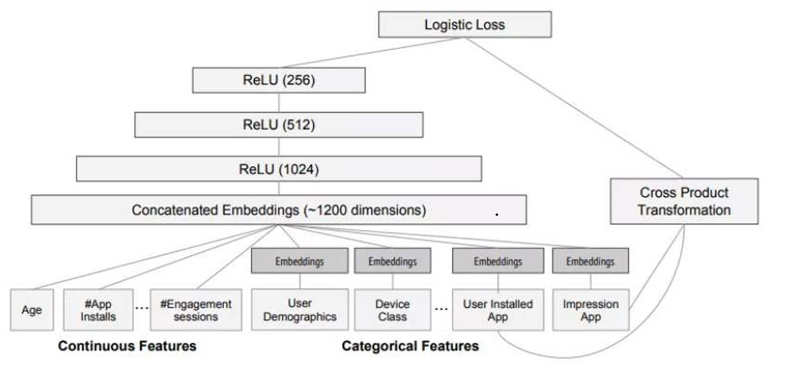
Deep模型
Deep部分的设计是为了模型具有较好的泛化能力,在输入的数据没有在训练集中出现时,它依然能够保持相关性较好的输出。
在下图中,Deep模型输入都是一些含义不是非常明显的特征,例如设备类型,用户统计数据等类别特征(Categorical Features)。类别特征一般属于高维特征。例如手机的种类可能存在成千上万个,因此我们通常把这些类别特征通过嵌入(Embedding)的方式,映射成低维空间的参数向量。这个向量可以被认为表示了原先这个类别特征的信息。对于连续特征,其数值本身就具备一定的含义,因此可以直接将其与其他嵌入向量进行拼接。在拼接完成后,可以得到大致为1200维度的向量。将其作为三层全连接层网络的输入,并且选择ReLU作为激活函数,其中每层的输出维度分别为[1024, 512, 256]。
在广告点击率预估的场景中,模型的输出是一个0-1之间的值,表示当前候选APP被点击的概率。因此可以采用逻辑回归函数,将Wide&Deep部分的输出压缩到0~1在之间。首先,Deep部分的输出是一个256维度的向量,可以通过一个线性变换将其映射为维度为1的值,然后和Wide部分的输出进行求和,将求和后的结果输入到逻辑回归函数中。
这个求和的过程就是结合两个部分的优点的过程。
4.在学习过程中遇到的疑问
Wide部分和Deep部分的能力有什么不同?- Wide部分是一个简单的宽线性模型,形如
y = w*x这样的式子,输入样本的属性对权重的计算产生直接的影响,假如A属性取1,最后模型输出1(真实值为0),那么通过Loss来调整w权重,w就应该变为0,所以Wide模型能够学习到那些直接在样本中出现过的交叉特征,学习历史出现过的组合,出现频率高,给予高权重。 - Deep部分通过一个神经网络来逼近一个高维函数,并通过该函数来计算出那些并不直接出现在训练样本中的交叉特征,这就是Deep模型的泛化能力,包含五层全连接层的深度神经网络,能深入这个高维函数的本质规则,抽象出最核心的问题。
- Wide部分是一个简单的宽线性模型,形如
- 什么是交叉特征?
- 交叉特征就是将原本的特征进行交叉组合,
形成新的特征,如有两个属性,一个是手机装了微信,另一个是手机装了QQ,组成新的交叉特征就是(装了微信,装了QQ)特征,该新特征为1时当且仅当两个属性都为真。
- 交叉特征就是将原本的特征进行交叉组合,

Wide和Deep模型是怎么联合输出的?- 公式:$P(Y=1|x) = \sigma(w_{\text{wide}}^T \cdot [x, \phi(x)] + w_{\text{deep}}^T \cdot a^{(l_f)} + b)$
- Wide模型的输出和Deep模型最后一个全连接层的输出直接加权相加(向量相加),在推荐系统的二分类场景中,Wide 和 Deep 部分的输出最终都被处理为维度相同的向量(通常是
[batch_size, 1]),表示每个样本的预测得分。
def construct(self, id_hldr, wt_hldr): # Wide部分计算 wide_id_weight = self.wide_embeddinglookup(id_hldr) wx = self.wide_mul(wide_id_weight, mask) wide_out = self.reshape(self.reduce_sum(wx, 1) + self.wide_b, (-1, 1)) # Deep部分计算 deep_id_embs = self.deep_embeddinglookup(id_hldr) vx = self.deep_mul(deep_id_embs, mask) deep_in = self.deep_reshape(vx, (-1, self.field_size * self.emb_dim)) deep_in = self.dense_layer_1(deep_in) deep_in = self.dense_layer_2(deep_in) deep_in = self.dense_layer_3(deep_in) deep_in = self.dense_layer_4(deep_in) deep_out = self.dense_layer_5(deep_in) # 联合输出:Wide与Deep的输出直接相加 out = wide_out + deep_out return out, self.embedding_table- 这种向量相加本质上实现了两种预测能力的融合:
- Wide 部分通过交叉特征(如 “性别 = 男 ∩ 商品 = 电子产品”)提供对高频模式的精确记忆。
- Deep 部分通过嵌入向量(如 “用户嵌入” 和 “商品嵌入” 的交互)挖掘特征间的潜在语义关联。
- 向量相加之后再接一个
sigmod激活函数输出被点击的概率
什么是dropout?- dropout随机丢弃部分神经元防止过拟合
什么是batch_size和epoch,它们之间的区别是什么?batch_size:表示并行训练的样本数,GPU擅长并行运算,所以batch_size越大,每次并行计算的数据就越多,显存要求越高,因为要存储每层网络的输入输出和参数之类的。batch_size影响训练速度和梯度稳定性,假如过大,epoch:表示样本的数据要重复训练多少次,控制学习轮次,影响模型对数据规律的掌握程度。- 对模型收敛的影响
- batch_size 影响梯度稳定性【梯度下降】3D可视化讲解通俗易懂_哔哩哔哩_bilibili
- 小 batch_size(如 8):每次梯度基于少量样本,波动大,可能跳出局部最优,但收敛过程更灵活。
- 大 batch_size(如 512):梯度基于大量样本平均,方向更稳定,但可能陷入尖锐局部最优。
- epoch 影响学习深度
- 合适的 epoch 数能让模型充分学习数据规律,避免
欠拟合(epoch 太少)或过拟合(epoch 太多)。 - 通过验证集监控损失变化,使用
早停策略(如验证集损失连续 5 轮不下降则停止)。
- 合适的 epoch 数能让模型充分学习数据规律,避免
什么叫做收敛稳定?- 在机器学习中,收敛稳定表示该网络的参数已经趋向于局部最优,损失值已经不再有明显的下降,修改权重带来的效果不在明显。这时候就可以结束训练。
batch_size和epoch之间的关系是什么?




