
Home - Django REST framework官方文档
0.为什么会有DRF
该部分的理解参考了此篇博客一图看懂Django和DRF - 知乎
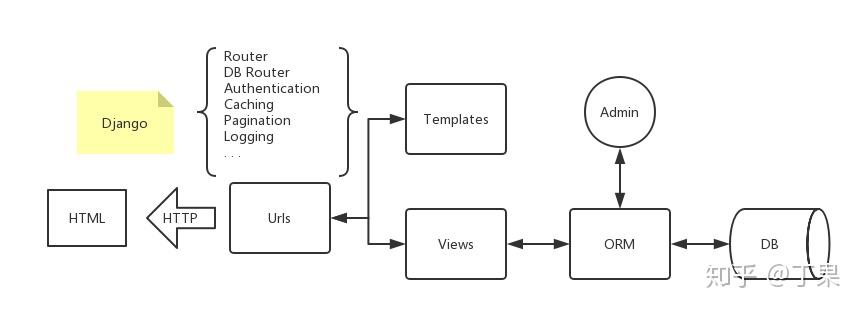
Django模板原生是为了进行前后端不分离的全栈开发,而前后端分离是一种现代化的开发模式和架构模式,旨在通过将前端和后端的职责分离来提升开发效率、系统性能和可维护性。DRF就是专为前后端分离架构来设计的一套WebAPI的框架。
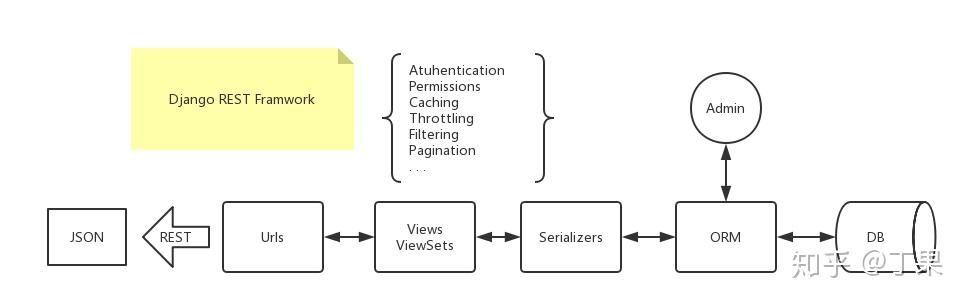
DRF是Django的超集,去掉了模板的部分,提供了一个REST风格的接口,同时也提供了满足该接口的代码工作流。同时,在REST的规范下,升级了权限和分页等功能,增加了限流和过滤搜索等功能。
0.1 环境配置
首先,使用pip下载第三方依赖包
pip install djangorestframework
pip install markdown # Markdown support for the browsable API.
pip install django-filter # Filtering support然后在Django的settings.py中注册rest_framwork
INSTALLED_APPS = [
...
'rest_framework',
]如果您打算使用可浏览的API,您可能还需要添加 REST 框架的登录和注销视图。将以下内容添加到您的根文件urls.py中
urlpatterns = [
...
path('api-auth/', include('rest_framework.urls'))
]请注意,URL 路径可以是您想要的任何路径。
REST 框架 API 的任何全局设置都保存在名为settings.py的文件,首先将以下内容添加到您的模块中:
REST_FRAMEWORK = {
# Use Django's standard `django.contrib.auth` permissions,
# or allow read-only access for unauthenticated users.
'DEFAULT_PERMISSION_CLASSES': [
'rest_framework.permissions.DjangoModelPermissionsOrAnonReadOnly'
]
}我们现在已准备好创建我们的 API。 这是我们项目的根模块:urls.py
from django.urls import path, include
from django.contrib.auth.models import User
from rest_framework import routers, serializers, viewsets
# Serializers define the API representation.
class UserSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = User
fields = ['url', 'username', 'email', 'is_staff']
# ViewSets define the view behavior.
class UserViewSet(viewsets.ModelViewSet):
queryset = User.objects.all()
serializer_class = UserSerializer
# Routers provide an easy way of automatically determining the URL conf.
router = routers.DefaultRouter()
router.register(r'users', UserViewSet)
# Wire up our API using automatic URL routing.
# Additionally, we include login URLs for the browsable API.
urlpatterns = [
path('', include(router.urls)),
path('api-auth/', include('rest_framework.urls', namespace='rest_framework'))
]现在,您可以在浏览器中打开 http://127.0.0.1:8000/ API,并查看新的“用户”API。如果您使用右上角的登录控件,您还可以从系统中添加、创建和删除用户。
0.2 API文档的自动生成
django rest framework 使用api接口文档_django自带的api接口文档-CSDN博客
如何自定义视图的文档说明?
只需要在对应的APIView或者ViewSet中添加注释,DRF会自动识别注释里面的内容添加到对应的接口文档中的方法说明。
- 假如没有方法如(list: create:)这些,将会将下面的文字应用到所有的接口。
- 假如有以下格式,将会按照对应的接口来生成文档说明。
class BookInfoViewSet(ModelViewSet):
"""
list:
返回所有图书
create:
创建图书
retrieve:
返回指定图书
update:
更新指定图书
partial_update:
部分更新指定图书
destroy:
删除指定图书
"""
queryset = Book.objects.all() # 指定视图集使用的查询集
serializer_class = BookSerializer # 指定该视图集使用的序列化器
@action(methods=['get'], detail=False)
# 生成的路由就是这样的:/books/get_book_author_list/?author=Tom
def get_book_author_list(self, request):
author = request.query_params.get('author')
book_list = Book.objects.filter(author__name=author)
seri_data = BookSerializer(book_list, many=True)
return Response(seri_data.data)
1.改进的特点 - 序列化和视图
1.1 序列化
首先什么是序列化和反序列化? 在我的理解中,因为在网络上传输的是字符串,需要将对象和其属性转化成对应的字符串,所以就是用序列器ModelSerializer来对模型对象转成字典来处理(也就是所谓的序列化),否则的话就是调用原生的__str__方法
”序列化(Serialization)是一种将数据结构或对象的状态转换成一种可以存储或传输的形式的过程。通过序列化,可以将复杂的数据结构(如对象、数组、字典等)转化为字符串或二进制格式,以便将其保存到文件、数据库中,或者通过网络在不同的系统之间传递。序列化的逆过程称为反序列化(Deserialization),即将序列化后的数据还原为原始的数据结构或对象。“
| 场景 | 原生 Django | DRF 序列化器 |
|---|---|---|
| 默认输出格式 | 调用 __str__ 方法(字符串) |
自定义字段结构(字典 / 列表) |
| 关联对象处理 | 需手动访问关联字段(如 book.author.name) |
使用 PrimaryKeyRelatedField 等自动处理 |
| 数据类型转换 | 需在模板中手动格式化(如日期) | 自动处理序列化(如日期转字符串) |
| API 响应 | 需手动构建字典 / JSON | 自动生成符合 REST 规范的响应 |
那就让我们来简单的实现一个序列化器:
# models.py中创建的模型字段
class Author(models.Model):
name = models.CharField(max_length=100)
class Book(models.Model):
title = models.CharField(max_length=100)
author = models.ForeignKey(to=Author, on_delete=models.CASCADE)
# 应用中新建serializers.py来创建具体的模型序列化器
from rest_framework import serializers
class BookSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = Book # 指定该序列化器对应的模型
fields = '__all__' # 序列化该模型的所有字段
# 在视图函数中尝试打印一个序列化后的对象看看
# 测试序列化器的函数
def test(request):
book = Book.objects.get(id=1) # 获取一个图书对象
serializer = BookSerializer(book) # 创建序列化器对象
print(serializer.data) # 输出序列化后的数据
return HttpResponse('ok')
"""
最后输出 {'id': 1, 'title': '水浒传', 'author': 1}
"""1.2 Serializer序列化器的简单使用
参考博客 Django REST framework序列化器详解:普通序列化器与模型序列化器的选择与运用_django序列化器-CSDN博客
a. 创建序列化器对象
定义好序列化器类之后,可以通过以下方式创建序列化器对象:
serializer = BookInfoSerializer(instance=book) # 用于序列化对象Serializer 类的构造方法是:
Serializer(instance=None, data=empty, **kwargs)instance用于传入需要序列化的模型实例。data用于传入需要反序列化的JSON数据。context参数用于传递额外的数据(如请求对象),可以在序列化器内部使用。
例如:
serializer = BookInfoSerializer(book, context={'request': request})b. 基本操作
例如,查询一个图书对象并进行序列化:
from booktest.models import BookInfo
book = BookInfo.objects.get(id=2) # 获取一个图书对象接下来,创建序列化器并获取序列化后的数据:
from booktest.serializers import BookInfoSerializer
serializer = BookInfoSerializer(book) # 创建序列化器对象
print(serializer.data) # 输出序列化后的数据输出结果类似:
{
"id": 2,
"btitle": "天龙八部",
"bpub_date": "1986-07-24",
"bread": 36,
"bcomment": 40,
"image": null
}如果需要序列化多个对象(如查询集),可以通过设置 many=True 来进行:
book_qs = BookInfo.objects.all() # 获取所有图书
serializer = BookInfoSerializer(book_qs, many=True) # 序列化多个对象
print(serializer.data)
"""或者说处理多对多关系 一个文章可以有多个标签tag"""
class ArticleSerializer(serializers.ModelSerializer):
tags = serializers.PrimaryKeyRelatedField(
many=True, # 允许多个标签 ID
queryset=Tag.objects.all()
)
# 接收数据: {"tags": [1, 3, 5]}输出结果类似:
[
{
"id": 2,
"btitle": "天龙八部",
"bpub_date": "1986-07-24",
"bread": 36,
"bcomment": 40,
"image": null
},
{
"id": 3,
"btitle": "笑傲江湖",
"bpub_date": "1990-05-01",
"bread": 25,
"bcomment": 35,
"image": null
}
]c.关联对象嵌套序列化
如果模型中包含关联字段(如外键),比如说你将Book对象进行序列化的时候还希望知道有关外键(作者)的其他信息,我们可以使用以下方式对关联对象进行序列化。
"""
当你查询一本书时,API 通常会返回作者的 ID(比如 author_id=2),而不是整个作者对象的详细信息。这就是 PrimaryKeyRelatedField 做的事情:用主键(ID)表示关联关系。
"""
class Author(models.Model):
name = models.CharField(max_length=100)
class Book(models.Model):
title = models.CharField(max_length=200)
author = models.ForeignKey(Author, on_delete=models.CASCADE)
"""
如果直接序列化 Book 对象,默认会返回:
{
"id": 1,
"title": "Python Crash Course",
"author": 2 # 作者的 ID
}
但是无法做到以下操作,因为还只是进行了单表查询
- 验证这个 author=2 是否真的存在于数据库中。
- 创建新书时,通过 author=2 自动关联对应的作者对象。
这就是 PrimaryKeyRelatedField 的核心作用:验证主键,并处理关联关系。
但是假如我们指定了PrimaryKeyRelatedField
"""
class BookSerializer(serializers.ModelSerializer):
# 指定 author 字段使用 PrimaryKeyRelatedField
author = serializers.PrimaryKeyRelatedField(queryset=Author.objects.all())
class Meta:
model = Book
fields = ['id', 'title', 'author']
"""在序列化的时候可能作用不是很明显"""
book = Book.objects.get(id=1)
serializer = BookSerializer(book)
print(serializer.data) # 输出: {'id': 1, 'title': 'Python', 'author': 2}
"""但是在反序列化的时候十分有用 反序列化(从 JSON 到模型)"""
# 客户端提交的数据
data = {
"title": "New Book",
"author": 2 # 假设作者 ID=2 存在
}
serializer = BookSerializer(data=data)
if serializer.is_valid(): # 在此处就会判断对应的author是否存在
book = serializer.save() # 自动关联 ID=2 的作者
print(book.author.name) # 输出: "John Doe"参数:
queryset参数 用于对关联的对象集进行一些条件限制many=True参数,用于序列化多个对象label属性,主要在API文档、表单渲染或错误信息中作为字段的显示名称。
"""queryset限制条件"""
# 只允许关联已激活的作者
author = serializers.PrimaryKeyRelatedField(
queryset=Author.objects.filter(is_active=True)
)
from rest_framework import serializers
"""label属性使用"""
class MySerializer(serializers.Serializer):
# 显式指定 label
email = serializers.EmailField(label="电子邮箱")
# 也可以在 ModelSerializer 中使用
class Meta:
model = User
fields = ['username', 'email']
extra_kwargs = {
'username': {'label': '用户名'},
'email': {'label': '电子邮箱'}
}- StringRelatedField
将关联对象序列化为其 __str__ 方法的返回值(对象的字符串表示形式)。掌握Python中_str_()方法的实用技巧 - 知乎
hbook = serializers.StringRelatedField(label='图书')- HyperlinkedRelatedField
该字段将关联对象序列化为一个超链接(URL),指向该对象的详细页面。
hbook = serializers.HyperlinkedRelatedField(label='图书', read_only=True, view_name='books-detail')view_name 必须指定为视图的名称,以便 DRF 可以找到对应的路由并生成URL。
- SlugRelatedField
该字段将关联对象序列化为指定字段的数据。
hbook = serializers.SlugRelatedField(label='图书', read_only=True, slug_field='bpub_date')- 使用自定义序列化器
我们还可以通过自定义序列化器来序列化关联对象。
hbook = BookInfoSerializer()- 重写
to_representation方法
通过重写 to_representation 方法,我们可以自定义如何序列化字段数据。比如,我们可以自定义一个关联字段来输出不同格式的数据:
class BookRelateField(serializers.RelatedField):
"""自定义图书字段的序列化"""
def to_representation(self, value):
return 'Book: %d %s' % (value.id, value.btitle)
hbook = BookRelateField(read_only=True)1.3 反序列化
a.验证
使用序列化器进行反序列化时,需要对数据进行验证后,才能获取验证成功的数据或保存成模型类对象。
在获取反序列化的数据前,必须调用**is_valid()**方法进行验证,验证成功返回True,否则返回False。
验证失败,可以通过序列化器对象的errors属性获取错误信息,返回字典,包含了字段和字段的错误。如果是非字段错误,可以通过修改REST framework配置中的NON_FIELD_ERRORS_KEY来控制错误字典中的键名。
使用django的后端验证错误消息 - 腾讯云开发者社区 - 腾讯云具体的有关字段错误和非字段错误可以自行搜索一下。
验证成功,可以通过序列化器对象的validated_data属性获取数据。
在定义序列化器时,指明每个字段的序列化类型和选项参数,本身就是一种验证行为。
is_valid()方法还可以在验证失败时抛出异常serializers.ValidationError,可以通过传递raise_exception=True参数开启,REST framework接收到此异常,会向前端返回HTTP 400 Bad Request响应。
- 当验证失败时,可以通过
serializer.errors获取错误信息。错误信息以字典形式返回,包含了字段和字段的错误。 - 验证成功后,可以通过
serializer.validated_data获取验证后的数据。
from rest_framework import serializers
# 定义序列化器
class UserSerializer(serializers.Serializer):
username = serializers.CharField(max_length=10)
age = serializers.IntegerField(min_value=18)
# 模拟传入的数据
data = {
"username": "this_is_too_long_for_the_field", # 超过最大长度
"age": 15 # 未达到最小年龄
}
# 序列化器实例
serializer = UserSerializer(data=data)
# 验证数据
if not serializer.is_valid():
print("验证失败,错误信息:")
print(serializer.errors)
# 输出错误信息:
# 验证失败,错误信息:
# {
# "username": ["Ensure this field has no more than 10 characters."],
# "age": ["Ensure this value is greater than or equal to 18."]
# }- 使用
raise_exception=True抛出异常
当调用 is_valid() 时,传递 raise_exception=True 参数,会在验证失败时抛出 serializers.ValidationError 异常。对于 REST framework,这种异常会自动返回 HTTP 400 Bad Request 响应。
from rest_framework.exceptions import ValidationError
data = {
"username": "invalid_user_name_because_it_is_too_long",
"age": 15
}
serializer = UserSerializer(data=data)
try:
serializer.is_valid(raise_exception=True)
except serializers.ValidationError as e:
print("捕获到 ValidationError 异常!")
print(e)
# 输出:
# 捕获到 ValidationError 异常!
# {'username': ['Ensure this field has no more than 10 characters.'], 'age': ['Ensure this value is greater than or equal to 18.']}
- 修改
NON_FIELD_ERRORS_KEY
如果需要自定义非字段错误的键名,可以在 REST framework 的全局配置中设置 NON_FIELD_ERRORS_KEY。
修改配置:
在 settings.py 中:
REST_FRAMEWORK = {
'NON_FIELD_ERRORS_KEY': 'non_field_errors'
}示例:
class CustomSerializer(serializers.Serializer):
name = serializers.CharField()
password = serializers.CharField()
def validate(self, data):
if data['name'] == data['password']:
raise serializers.ValidationError("用户名和密码不能相同") # 这是一个非字段错误
return data
data = {
"name": "admin",
"password": "admin"
}
serializer = CustomSerializer(data=data)
if not serializer.is_valid():
print(serializer.errors)
# 输出:
# {'non_field_errors': ['用户名和密码不能相同']b.保存
如果在验证成功后,想要基于validated_data完成数据对象的创建,可以通过实现create()和update()两个方法来实现。
create()方法:当调用save()时,如果序列化器在初始化时没有传递instance,则会调用create()方法,用于创建新的对象。update()方法:当调用save()时,如果序列化器在初始化时传递了instance,则会调用update()方法,用于更新现有对象。
示例代码:
from rest_framework import serializers
# 定义一个简单的模型类
class User:
def __init__(self, username, age):
self.username = username
self.age = age
# 定义序列化器
class UserSerializer(serializers.Serializer):
username = serializers.CharField(max_length=10)
age = serializers.IntegerField(min_value=18)
# create 方法
def create(self, validated_data):
return User(**validated_data) # 创建新的对象
# update 方法
def update(self, instance, validated_data):
instance.username = validated_data.get('username', instance.username)
instance.age = validated_data.get('age', instance.age)
return instance
# 使用 create() 创建对象
data = {"username": "testuser", "age": 25}
serializer = UserSerializer(data=data)
if serializer.is_valid():
user = serializer.save() # 调用 create() 方法
print("创建的用户对象:", user.__dict__)
# 使用 update() 更新对象
existing_user = User(username="olduser", age=30)
update_data = {"username": "updateduser"}
serializer = UserSerializer(instance=existing_user, data=update_data, partial=True)
if serializer.is_valid():
updated_user = serializer.save() # 调用 update() 方法
print("更新后的用户对象:", updated_user.__dict__)- 在
save()时传递额外数据
可以在调用 save() 方法时传递额外的数据,这些数据会被传递到 create() 或 update() 方法的 validated_data 参数中。
示例代码:
class UserSerializer(serializers.Serializer):
username = serializers.CharField(max_length=10)
age = serializers.IntegerField(min_value=18)
def create(self, validated_data):
# 获取额外传递的数据
extra_info = validated_data.pop('extra_info', None)
print("额外信息:", extra_info)
return User(**validated_data)
data = {"username": "newuser", "age": 20}
serializer = UserSerializer(data=data)
if serializer.is_valid():
user = serializer.save(extra_info="This is extra data") # 传递额外的数据,会添加到对应的validated_data字典中
print("创建的用户对象:", user.__dict__)- 使用
partial=True进行部分字段更新
默认情况下,序列化器会对所有 required=True 的字段进行验证。如果只想更新部分字段,可以在创建序列化器时传递 partial=True,允许跳过未提供的字段的验证。
示例代码:
# 使用 partial=True 进行部分字段更新
existing_user = User(username="partialuser", age=40)
update_data = {"age": 45} # 仅更新部分字段
serializer = UserSerializer(instance=existing_user, data=update_data, partial=True)
if serializer.is_valid():
updated_user = serializer.save()
print("部分更新后的用户对象:", updated_user.__dict__)1.4 模型序列化器
参考博客 Django REST Framework(DRF)框架之Serializer序列化器的使用
模型序列化器其实已经在上面的代码例子中演示过了,ModelSerializer 是 Django REST Framework (DRF) 提供的一个基于 Django 模型的序列化器。它可以让你快速创建一个与模型类相关联的序列化器,而无需手动为每个字段定义逻辑。
定义一个 ModelSerializer 很简单,继承自 serializers.ModelSerializer 并定义 Meta 类即可。
from rest_framework import serializers
from myapp.models import MyModel
class MyModelSerializer(serializers.ModelSerializer):
class Meta:
model = MyModel # 指定对应的模型类
fields = '__all__' # 或指定具体字段列表a. 指定字段-Meta类的属性
- 使用
fields明确字段
使用 fields 属性可以指定序列化器要包含的字段,可以使用 __all__ 表示包含模型的所有字段,也可以指定具体字段。
class MyModelSerializer(serializers.ModelSerializer):
class Meta:
model = MyModel
fields = ['id', 'name', 'description'] # 指定具体字段- 使用
exclude排除字段
使用 exclude 属性可以指定要排除的字段,fields 和 exclude 不能同时使用。
class MyModelSerializer(serializers.ModelSerializer):
class Meta:
model = MyModel
exclude = ['created_at', 'updated_at'] # 排除某些字段- 使用
depth生成嵌套表示
默认情况下,ModelSerializer 使用主键(id)作为关联字段。如果需要嵌套表示,可以使用 depth 属性。depth 是一个整数,用来指明嵌套的层级数量。
注意:此时不要设置PrimaryKeyRelatedField等关联规则,否则序列化结果只包含author的id属性。
示例:
假设有两个模型:
class Category(models.Model):
name = models.CharField(max_length=255)
class Product(models.Model):
name = models.CharField(max_length=255)
category = models.ForeignKey(Category, on_delete=models.CASCADE)序列化器如下:
class ProductSerializer(serializers.ModelSerializer):
class Meta:
model = Product
fields = '__all__'
depth = 1 # 嵌套层级为1序列化后的数据可能是:
{
"id": 1,
"name": "Product A",
"category": {
"id": 2,
"name": "Category B"
}
}- 显式指定字段
如果需要对某个字段进行特殊处理,可以在序列化器中显式自定义字段。例如:
class BookSerializer(serializers.ModelSerializer):
days_since_published = serializers.SerializerMethodField() # 自定义只读字段,注意自定义字段只能使用SerializerMethodField(),否则就需要在__init__()方法中定制
class Meta:
model = Book
fields = ['id', 'title', 'pub_date', 'days_since_published']
# get_加上你自定义的字段 就是序列器在序列化的时候计算的属性,obj参数就是传过来的book实例
def get_days_since_published(self, obj):
"""计算书籍出版天数"""
from django.utils import timezone
if obj.pub_date:
return (timezone.now().date() - obj.pub_date).days
return None- 指定只读字段
可以使用 read_only_fields 属性指定只读字段,这些字段仅用于序列化输出,不能用于反序列化输入。
class MyModelSerializer(serializers.ModelSerializer):
class Meta:
model = MyModel
fields = '__all__'
read_only_fields = ['id', 'created_at'] # 指定只读字段b. 添加额外参数
在某些情况下,我们可能需要为序列化器的字段添加额外的选项或修改原有的字段行为,可以通过 extra_kwargs 实现。
- 验证器内容拓展:
class MyModelSerializer(serializers.ModelSerializer):
class Meta:
model = MyModel
fields = '__all__'
extra_kwargs = {
'name': {'required': True, 'validators': []}, # 设置 name 字段为必填,并取消其验证器
'description': {'max_length': 200}, # 设置 description 字段的最大长度
}c. 整合示例
from rest_framework import serializers
from myapp.models import Category, Product
class ProductSerializer(serializers.ModelSerializer):
category_name = serializers.CharField(source='category.name', read_only=True)
class Meta:
model = Product
fields = ['id', 'name', 'price', 'category', 'category_name']
read_only_fields = ['id']
extra_kwargs = {
'price': {'required': True, 'min_value': 0}, # 价格字段必须非负
'category': {'write_only': True}, # 分类字段仅用于写入(反序列化)
}通过 ModelSerializer,可以快速为模型类创建功能齐全的序列化器,同时保留灵活性以满足自定义需求。
1.5 优化的Request和Response对象
a. Request对象
在Django REST框架中,request对象已经不再是Django默认的HttpRequest对象,而是由REST框架提供的扩展版本,即Request对象。这个Request对象继承了HttpRequest,并加入了更多功能来处理API请求的数据。
当前端发起请求时,REST框架会根据请求的Content-Type(比如JSON、表单等)自动解析请求体中的数据。解析后,这些数据会以类字典对象的形式存储在Request对象中。这样,无论前端发送的数据格式是什么,我们都能通过统一的方式访问这些数据。
常用的属性:
request.data
这是请求体的数据。它的作用类似于Django中的request.POST和request.FILES,但是它有以下特点:
- 包含解析后的文件和非文件数据。
- 支持多种请求方式,如
POST、PUT、PATCH等。 - 通过REST框架的解析器(
parsers)解析,不仅支持表单数据,还支持JSON数据。
request.query_params
这个属性类似于Django中的request.GET,用于获取请求URL中的查询参数(即?key=value部分)。request.query_params只是REST框架对request.GET的改进,名字更准确一些。
简而言之,request.data用于访问请求体的数据(比如表单数据或JSON),而request.query_params用于获取URL中的查询参数。这样,不论前端发送何种格式的数据,都可以统一通过这些属性来访问和处理请求数据。
b. Response的对象
在 Django REST framework 中,Response 是一个用来构造 HTTP 响应的类。它会根据前端的实际需求自动将 Python 数据转换为适合的格式(比如 JSON、HTML 等)。这个转换过程是通过 渲染器(Renderer) 来完成的。
响应的渲染机制
通过前端请求中的 Accept 请求头,REST framework 会选择最佳的渲染器将数据转换为对应格式。如果前端未指定 Accept,系统会使用默认的渲染器来处理响应数据。默认渲染器可以在项目的配置中修改:
REST_FRAMEWORK = {
'DEFAULT_RENDERER_CLASSES': (
'rest_framework.renderers.JSONRenderer', # JSON 渲染器(默认返回 JSON 格式数据)
'rest_framework.renderers.BrowsableAPIRenderer', # 可浏览的 API 页面渲染器
)
}构造响应
Response 类的构造方法如下:
Response(data, status=None, template_name=None, headers=None, content_type=None)这里的 data 参数,只需要传入 Python 内置类型的数据(例如字典、列表、字符串等),而不需要是已经处理好的(渲染后的)数据。REST framework 会根据请求头和配置自动进行渲染。如果传入的是复杂结构(例如 Django 的模型对象),需要先通过 序列化器(Serializer) 转换为适合的格式(通常为字典)后再传递给 data。
参数说明:
- data: 要返回的响应数据,必须是序列化后的 Python 内置类型(如字典、列表等)。
- status: HTTP 状态码,默认为
200(成功)。 - template_name: 如果渲染器是
HTMLRenderer,可指定使用的模板名称。 - headers: 一个字典,指定响应头信息。
- content_type: 响应的
Content-Type,通常无需指定,REST framework 会自动根据渲染数据类型生成。
常用属性
.data
这个属性是传给Response的原始数据,还没有经过渲染器处理(也就是“尚未转换为最终响应格式”的数据)。例如,传入一个字典,它就是你未加工的字典。.status_code
响应的 HTTP 状态码,例如200表示成功,404表示资源未找到。.content
这是最终处理完成的响应数据。它会经过渲染器的转换(例如转换为 JSON 格式字符串),最终成为 HTTP 响应体中返回的内容。
c. 示例代码:简单演示
from rest_framework.response import Response
from rest_framework.views import APIView
class MyApiView(APIView):
def get(self, request):
# 原始数据
data = {
'message': 'Hello, World!',
'status': 'success'
}
# 返回响应
return Response(data, status=200)在上面的例子中:
.data是{'message': 'Hello, World!', 'status': 'success'},即传入的原始数据。.status_code是200,表示成功。.content是{"message":"Hello, World!","status":"success"},即渲染器将数据转换为 JSON 格式的字符串。
只需要传入 Python 的原始数据,框架会根据前端的需求和配置自动完成数据格式的转换和响应构造,大大简化了开发流程。
DRF 的
CBV将 HTTP 请求方法(GET、POST、PUT、DELETE 等)映射到类中同名的方法:
HTTP 方法 类方法名称 典型用途 GET get()查询单个资源或列表 POST post()创建新资源 PUT put()完整更新资源(需提供全部字段) PATCH patch()部分更新资源(仅提供需修改的字段) DELETE delete()删除资源 OPTIONS options()返回 API 元信息(自动生成) HEAD head()返回资源头部信息(自动生成) 这种映射机制由 DRF 的
APIView基类实现,通过dispatch()方法根据请求类型调用对应的处理函数。
1.6 DRF 的 URL 路由方式
DRF 提供了多种路由方式,从低级到高级依次为:
a. 手动配置(适合简单 API)
直接使用 path() 或 re_path() 映射到 DRF 的视图类:
# views.py
from rest_framework.response import Response
from rest_framework.views import APIView
class ArticleList(APIView):
def get(self, request):
return Response({"message": "文章列表"})
class ArticleDetail(APIView):
def get(self, request, pk):
return Response({"message": f"文章 {pk}"})
# urls.py
from django.urls import path
from .views import ArticleList, ArticleDetail
urlpatterns = [
path('articles/', ArticleList.as_view(), name='article-list'),
path('articles/<int:pk>/', ArticleDetail.as_view(), name='article-detail'),
]b. 使用 generics 通用视图
DRF 的 generics 模块提供了预定义的视图类(如 ListAPIView、RetrieveAPIView)
# views.py
from rest_framework import generics
from .models import Article
from .serializers import ArticleSerializer
class ArticleList(generics.ListCreateAPIView):
queryset = Article.objects.all()
serializer_class = ArticleSerializer
class ArticleDetail(generics.RetrieveUpdateDestroyAPIView):
queryset = Article.objects.all()
serializer_class = ArticleSerializer
# urls.py
urlpatterns = [
path('articles/', ArticleList.as_view(), name='article-list'),
path('articles/<int:pk>/', ArticleDetail.as_view(), name='article-detail'),
]c. 使用 ViewSet 和 Router
DRF 的 ViewSet 和 Router 可以自动生成 URL 映射:
# views.py
from rest_framework import viewsets
from .models import Article
from .serializers import ArticleSerializer
class ArticleViewSet(viewsets.ModelViewSet):
queryset = Article.objects.all()
serializer_class = ArticleSerializer
# urls.py
from django.urls import include, path
from rest_framework.routers import DefaultRouter
router = DefaultRouter()
router.register(r'article', ArticleViewSet) # 自动生成 URL 映射
urlpatterns = [
path('', include(router.urls)), # 包含自动生成的 URL
]自动生成的 URL 示例:
GET /article/ → ArticleViewSet.list()
POST /article/ → ArticleViewSet.create()
GET /article/1/ → ArticleViewSet.retrieve()
PUT /article/1/ → ArticleViewSet.update()
DELETE /article/1/ → ArticleViewSet.destroy()1.7 DRF封装的状态编码
在DRF框架中,为了更方便地设置 HTTP 状态码,框架在 rest_framework.status 模块中定义了一系列常用的状态码常量。这些常量是标准的 HTTP 状态码表示,使用这些常量可以让代码更加清晰易读,也有助于减少拼写错误。
HTTP 状态码根据用途分为 5 大类:
| 类别 | 状态码范围 | 含义 | 典型场景示例 |
|---|---|---|---|
| 1xx 信息性状态码 | 100-199 | 请求已接收,继续处理 | 100 Continue(客户端继续发送请求) |
| 2xx 成功状态码 | 200-299 | 请求成功处理 | 200 OK(查询成功)、201 Created(资源创建) |
| 3xx 重定向状态码 | 300-399 | 请求需要进一步操作 | 301 Moved Permanently(永久重定向) |
| 4xx 客户端错误状态码 | 400-499 | 客户端请求有误 | 400 Bad Request(参数错误)、401 Unauthorized(未认证) |
| 5xx 服务器错误状态码 | 500-599 | 服务器处理请求时出错 | 500 Internal Server Error(服务器内部错误) |
DRF中对于请求码常量的变量名格式定义遵循HTTP_状态码_英文描述规则:
| DRF 常量 | 状态码 | 适用场景 |
|---|---|---|
HTTP_200_OK |
200 | 查询资源成功(如 GET 请求返回数据) |
HTTP_201_CREATED |
201 | 创建资源成功(如 POST 请求创建新数据) |
HTTP_204_NO_CONTENT |
204 | 操作成功但无返回内容(如 DELETE 请求删除资源后) |
HTTP_400_BAD_REQUEST |
400 | 客户端请求参数错误(如 JSON 格式错误、必填字段缺失) |
HTTP_401_UNAUTHORIZED |
401 | 用户未认证(如 Token 过期、未提供认证信息) |
HTTP_403_FORBIDDEN |
403 | 用户认证通过但无权限(如角色权限不足) |
HTTP_404_NOT_FOUND |
404 | 资源不存在(如访问不存在的 URL 或 ID) |
HTTP_500_INTERNAL_SERVER_ERROR |
500 | 服务器内部错误(如代码异常、数据库连接失败) |
注意:状态码的使用可以通过在Response对象的status参数中设置
from rest_framework import status
from rest_framework.response import Response
from rest_framework.views import APIView
class UserView(APIView):
def get(self, request, pk):
try:
user = User.objects.get(pk=pk)
return Response({"data": user.data}, status=status.HTTP_200_OK)
except User.DoesNotExist:
return Response({"error": "用户不存在"}, status=status.HTTP_404_NOT_FOUND)
def post(self, request):
serializer = UserSerializer(data=request.data)
if serializer.is_valid():
serializer.save()
# 创建成功返回201,且返回新资源的URL
return Response(
serializer.data,
status=status.HTTP_201_CREATED,
headers={"Location": f"/users/{serializer.data['id']}"}
)
# 校验失败返回400,错误信息包含具体字段问题
return Response(
serializer.errors,
status=status.HTTP_400_BAD_REQUEST
)更加具体的可以看django rest framwork的详细文档Status codes - Django REST framework
1.8 更高级的视图基类
在 Django REST framework 中,视图是处理 HTTP 请求并返回响应的核心组件。REST framework 提供了很多类和方法来简化视图的编写,下面将详细介绍几种常见的视图基类和扩展类,并配上通俗易懂的代码示例。
a. APIView
APIView 是 Django REST framework 提供的所有视图的基类,继承自 Django 的 View 类。
与 Django 的普通 View 的区别:
- 在
APIView中,传入视图方法的请求对象是 REST framework 的Request对象,而不是 Django 的HttpRequest对象。 - 视图方法可以返回
Response对象,响应的数据会自动根据前端的需求进行格式化(例如 JSON 格式)。 - 如果发生
APIException异常,它会被自动捕获并转换为合适的响应信息。 - 在调用
dispatch()方法前,框架会自动进行身份认证、权限检查和流量控制等操作。
常用属性:
authentication_classes:指定身份认证类。permission_classes:指定权限控制类。throttle_classes:指定流量控制类。
示例:
from rest_framework.views import APIView
from rest_framework.response import Response
from .models import BookInfo
from .serializers import BookInfoSerializer
class BookListView(APIView):
def get(self, request):
# 获取所有书籍数据
books = BookInfo.objects.all()
serializer = BookInfoSerializer(books, many=True)
return Response(serializer.data)在这个例子中,BookListView 继承自 APIView,并通过 get() 方法返回书籍列表。
b. GenericAPIView
GenericAPIView 继承自 APIView,增加了对列表视图和详情视图常用方法的支持,通常与 Mixin 类一起使用。
常用属性:
queryset:列表视图查询的数据集。serializer_class:使用的序列化器类。
常用方法:
get_queryset():获取查询集的方法。get_serializer_class():获取序列化器类的方法。
示例:
from rest_framework.generics import GenericAPIView
from rest_framework.response import Response
from .models import BookInfo
from .serializers import BookInfoSerializer
class BookDetailView(GenericAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
def get(self, request, pk):
# 获取单本书籍数据
book = self.get_object() # 获取单一数据对象
serializer = self.get_serializer(book) # 序列化数据
return Response(serializer.data)这里的 BookDetailView 继承自 GenericAPIView,通过 get() 方法返回某本书籍的详细信息。
1.9 拓展视图类的功能(多重继承)
扩展类(Mixin)是为了简化常见的操作(如创建、更新、删除等),它们可以与 GenericAPIView 一起使用,提供快速实现常见视图功能的方法。
a. ListModelMixin
用于快速实现列表视图的功能。提供 list() 方法,返回符合过滤和分页条件的列表。
示例:
from rest_framework import mixins
from rest_framework import generics
from .models import BookInfo
from .serializers import BookInfoSerializer
class BookListView(mixins.ListModelMixin, generics.GenericAPIView):
queryset = BookInfo.objects.all() # list方法中将queryset的函数序列化之后返回
serializer_class = BookInfoSerializer
def get(self, request):
return self.list(request) # 使用 ListModelMixin 中的 list 方法b. CreateModelMixin
用于创建资源的视图。提供 create() 方法,成功时返回 201 状态码。
示例:
from rest_framework import mixins
from rest_framework import generics
from .models import BookInfo
from .serializers import BookInfoSerializer
class BookCreateView(mixins.CreateModelMixin, generics.GenericAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
def post(self, request):
return self.create(request) # 使用 CreateModelMixin 中的 create 方法c. RetrieveModelMixin
用于返回单个对象的详情视图。提供 retrieve() 方法。
示例:
from rest_framework import mixins
from rest_framework import generics
from .models import BookInfo
from .serializers import BookInfoSerializer
class BookDetailView(mixins.RetrieveModelMixin, generics.GenericAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
def get(self, request, pk):
return self.retrieve(request, pk) # 使用 RetrieveModelMixin 中的 retrieve 方法d. UpdateModelMixin
用于更新资源的视图。提供 update() 和 partial_update() 方法。
示例:
from rest_framework import mixins
from rest_framework import generics
from .models import BookInfo
from .serializers import BookInfoSerializer
class BookUpdateView(mixins.UpdateModelMixin, generics.GenericAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
def put(self, request, pk):
return self.update(request, pk) # 使用 UpdateModelMixin 中的 update 方法e. DestroyModelMixin
用于删除资源的视图。提供 destroy() 方法,成功时返回 204 状态码。
示例:
from rest_framework import mixins
from rest_framework import generics
from .models import BookInfo
from .serializers import BookInfoSerializer
class BookDeleteView(mixins.DestroyModelMixin, generics.GenericAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
def delete(self, request, pk):
return self.destroy(request, pk) # 使用 DestroyModelMixin 中的 destroy 方法1.10 ViewSet视图集
视图集(ViewSet) 是一个用来处理一组相关动作(如列出数据、创建数据、更新数据等)的大类。通过视图集,你可以将这些逻辑放在一个类里,而不需要分别为每个动作编写单独的视图函数。
常见的ViewSet动作
list():提供一组数据(如获取所有书籍)。retrieve():提供单个数据(如获取某本书的详细信息)。create():创建新数据(如添加一本新书)。update():更新数据(如修改一本书的信息)。destroy():删除数据(如删除一本书)。
在 ViewSet 中,不需要显式地定义APIView类的get()、post() 等方法,而是定义这些动作的方法(list()、create() 等)。当你调用 as_view() 时,框架会自动将请求与具体的动作方法(action)对应起来。
示例:
from rest_framework import viewsets
from rest_framework.response import Response
class BookInfoViewSet(viewsets.ViewSet):
def list(self, request):
# 返回所有书籍
books = BookInfo.objects.all()
return Response({'books': books})
def retrieve(self, request, pk=None):
# 返回单本书籍详情
book = BookInfo.objects.get(pk=pk)
return Response({'book': book})当我们定义了这样的 BookInfoViewSet 类后,路由的配置会将 HTTP 请求与相应的动作方法(如 list()、retrieve())关联起来:
设置路由
from django.urls import path
from .views import BookInfoViewSet
urlpatterns = [
# 注意 as_view()函数的参数,字典的键就是对应的HTTP请求的方法类型,而对应的值就是要调用的视图集中的对应方法 path('books/', BookInfoViewSet.as_view({'get': 'list'})), # 获取书籍列表
path('books/<int:pk>/', BookInfoViewSet.as_view({'get': 'retrieve'})), # 获取单本书籍
]action属性
在视图集中,action 属性可以帮助你判断当前请求执行的是哪个动作方法。例如,你可以根据 action 来决定使用哪个序列化器:
def get_serializer_class(self):
if self.action == 'create':
return BookCreateSerializer
else:
return BookListSerializer在这个例子中,如果 action 是 create,则使用 BookCreateSerializer,否则使用 BookListSerializer。
常用视图集父类
- ViewSet
ViewSet 是最基本的视图集类,它继承自 APIView。使用时需要自己定义具体的动作方法(如 list()、create() 等)。
- GenericViewSet
GenericViewSet 继承自 GenericAPIView,提供了常用的功能方法(如 get_queryset() 和 get_serializer_class()),简化了视图集的开发,特别适合用于列表视图和详情视图。
- ModelViewSet
ModelViewSet 继承自 GenericViewSet,并且包含了 ListModelMixin、RetrieveModelMixin、CreateModelMixin、UpdateModelMixin、DestroyModelMixin,因此它提供了对模型的增删改查(CRUD)操作,简化了视图集的实现。
- ReadOnlyModelViewSet
ReadOnlyModelViewSet 继承自 GenericViewSet,并包含了 ListModelMixin 和 RetrieveModelMixin,适用于只需要读取数据的视图集。
定义附加自定义动作
除了框架默认的动作(如 list()、retrieve()),你还可以在视图集中定义自定义的动作(action)。这些自定义动作通过 @action 装饰器来实现。
自定义动作
methods:指定此动作支持的 HTTP 请求方法(如GET、POST)。detail:指定动作是否是针对某个单独的对象(True表示针对某个对象,False表示不针对对象)。假如设置为True那就运行在接一层操作到对应主键的对象

代码示例:
from rest_framework.decorators import action
from rest_framework import viewsets
from rest_framework.response import Response
class BookInfoViewSet(viewsets.GenericViewSet, mixins.ListModelMixin, mixins.RetrieveModelMixin):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
@action(methods=['get'], detail=False)
def latest(self, request):
# 返回最新添加的书籍
latest_books = BookInfo.objects.order_by('-created_at')[:5]
return Response({'latest_books': latest_books})
@action(methods=['put'], detail=True)
def read(self, request, pk=None): # 使用pk=None参数
# 标记某本书为已读
book = self.get_object() # 在这里获取主键对应的对象
book.read = True
book.save()
return Response({'book': BookInfoSerializer(book).data})这个视图集类将会有两个自定义的动作:
latest:返回最新的 5 本书。read:更新某本书的状态为已读。
形成的路由:
正则^books/latest/$ name: book-latest
正则^books/{pk}/read/$ name: book-read自定义动作的路由参数
在 DRF 的 ViewSet 中,自定义动作(使用 @action 装饰器)添加参数主要通过 URL 路径参数、查询参数 和 请求体参数 三种方式实现。以下是详细的实现方法和示例:
- 通过 URL 路径参数传递(路径变量)
使用 detail=True 或 detail=False 参数,并在 URL 路径中定义变量。
from rest_framework.decorators import action
from rest_framework.response import Response
class UserViewSet(viewsets.ModelViewSet):
queryset = User.objects.all()
serializer_class = UserSerializer
@action(detail=True, methods=['get'], url_path=r'send-email/(?P<email_type>\w+)')
def send_email(self, request, pk=None, email_type=None):
"""
发送指定类型的邮件给用户
URL 示例:/users/123/send-email/activation/
"""
user = self.get_object()
# 根据 email_type 参数执行不同逻辑
if email_type == 'activation':
send_activation_email(user)
elif email_type == 'reset':
send_reset_email(user)
return Response({'status': f'{email_type} email sent'})关键参数说明
detail=True:表示该动作作用于单个对象,URL 中必须包含对象 ID(如/users/{id}/action/)。url_path:自定义 URL 路径,使用正则表达式捕获参数(如(?P<email_type>\w+))。
- 通过查询参数传递(GET 参数)
直接从 request.query_params 中获取参数,无需额外配置。
@action(detail=False, methods=['get'])
def search(self, request):
"""
根据关键词搜索用户
URL 示例:/users/search/?keyword=john&age=25
"""
keyword = request.query_params.get('keyword', '')
age = request.query_params.get('age')
queryset = self.get_queryset()
if keyword:
queryset = queryset.filter(username__icontains=keyword)
if age:
queryset = queryset.filter(age=age)
serializer = self.get_serializer(queryset, many=True)
return Response(serializer.data)参数校验建议
使用 DRF 的序列化器校验查询参数:
from rest_framework import serializers
class SearchSerializer(serializers.Serializer):
keyword = serializers.CharField(required=False)
age = serializers.IntegerField(required=False, min_value=0)
@action(detail=False, methods=['get'])
def search(self, request):
serializer = SearchSerializer(data=request.query_params)
serializer.is_valid(raise_exception=True)
# 使用校验后的数据
keyword = serializer.validated_data.get('keyword')
# ...- 通过请求体参数传递(POST/PUT/PATCH)
从 request.data 中获取参数,建议使用序列化器校验。
class ResetPasswordSerializer(serializers.Serializer):
old_password = serializers.CharField(required=True)
new_password = serializers.CharField(required=True, min_length=8)
@action(detail=True, methods=['post'])
def reset_password(self, request, pk=None):
"""
重置用户密码
请求体示例:{"old_password": "123456", "new_password": "new123456"}
"""
user = self.get_object()
serializer = ResetPasswordSerializer(data=request.data)
serializer.is_valid(raise_exception=True)
# 验证旧密码
if not user.check_password(serializer.validated_data['old_password']):
return Response({'error': '旧密码错误'}, status=400)
# 设置新密码
user.set_password(serializer.validated_data['new_password'])
user.save()
return Response({'status': '密码已重置'})综合的案例
@action(detail=True, methods=['post'], url_path=r'add-role/(?P<role_name>\w+)')
def add_role(self, request, pk=None, role_name=None):
"""
为用户添加指定角色
URL 示例:/users/123/add-role/admin/
请求体示例:{"expires_at": "2023-12-31"}
"""
user = self.get_object()
expires_at = request.data.get('expires_at')
# 添加角色逻辑
user.roles.add(Role.objects.get(name=role_name))
if expires_at:
user.role_expires = expires_at
user.save()
return Response({'status': f'已添加角色 {role_name}'})参数校验与错误处理
使用序列化器校验
对复杂参数(如请求体),始终使用 DRF 序列化器进行校验,自动处理错误返回。处理必填参数
在序列化器中设置required=True,或在代码中显式检查:keyword = request.query_params.get('keyword') if not keyword: return Response({'error': 'keyword 参数是必需的'}, status=400)自定义错误信息
通过error_messages参数定制错误提示:class SearchSerializer(serializers.Serializer): keyword = serializers.CharField( required=True, error_messages={'required': '请提供搜索关键词'} )
1.11 Router类
【9.0】DRF之路由 - Chimengmeng - 博客园
1. 两种主要路由类型
| 路由类型 | 特点 | 适用场景 |
|---|---|---|
SimpleRouter |
生成基础的 RESTful URL,如 /users/ 和 /users/{id}/ |
标准资源 CRUD 操作 |
DefaultRouter |
继承自 SimpleRouter,额外生成 API 根视图(带超链接)和可选格式后缀 |
需要自动生成 API 文档或超链接 |
2. 路由绑定的核心逻辑
- **视图集 (ViewSet)**:DRF 特有的视图类型,将相关操作(如
list、create、retrieve)组合到一个类中。 - 路由自动映射:通过
router.register()方法将视图集与 URL 前缀绑定,自动生成对应 URL 模式。
a. 使用 DefaultRouter 配置标准视图集
# urls.py
from rest_framework import routers
from .views import UserViewSet, GroupViewSet
# 创建路由器并注册视图集
router = routers.DefaultRouter()
router.register(r'users', UserViewSet) # 自动生成 /users/ 和 /users/{id}/
router.register(r'groups', GroupViewSet)
# 将生成的 URL 配置添加到 urlpatterns
urlpatterns = router.urlsb. 对应的视图集定义
# views.py
from rest_framework import viewsets
from .models import User, Group
from .serializers import UserSerializer, GroupSerializer
class UserViewSet(viewsets.ModelViewSet):
"""
自动提供 list、create、retrieve、update 和 destroy 操作
"""
queryset = User.objects.all()
serializer_class = UserSerializer
class GroupViewSet(viewsets.ModelViewSet):
queryset = Group.objects.all()
serializer_class = GroupSerializerc. 自动生成的URL模式
| HTTP 方法 | URL 路径 | 对应的视图方法 | 功能 |
|---|---|---|---|
| GET | /users/ |
list() |
获取用户列表 |
| POST | /users/ |
create() |
创建新用户 |
| GET | /users/{id}/ |
retrieve() |
获取单个用户详情 |
| PUT | /users/{id}/ |
update() |
完整更新用户信息 |
| PATCH | /users/{id}/ |
partial_update() |
部分更新用户信息 |
| DELETE | /users/{id}/ |
destroy() |
删除用户 |
使用 @action 装饰器为视图集添加自定义操作:
from rest_framework.decorators import action
from rest_framework.response import Response
class UserViewSet(viewsets.ModelViewSet):
queryset = User.objects.all()
serializer_class = UserSerializer
@action(detail=True, methods=['post']) # detail=True 表示针对单个对象
def reset_password(self, request, pk=None):
user = self.get_object()
# 重置密码逻辑
return Response({'status': 'password reset'})生成的 URL:/users/{id}/reset_password/ POST方法请求就会调用对应函数里的逻辑
1.12 APIView和ViewSet的选择
在 Django REST Framework (DRF) 中,APIView 和 ViewSet 是构建 API 视图的两种核心方式,它们的设计目标和适用场景不同。以下从功能对比、适用场景、实战建议三方面详细解析:
a. 核心区别:从设计目标理解
| 特性 | APIView | ViewSet |
|---|---|---|
| 设计理念 | 专注于 HTTP 方法(GET/POST/PUT/DELETE) | 专注于资源操作(List/Create/Retrieve/Update) |
| URL 定义方式 | 手动在 urls.py 中定义每个 URL 路径 |
通过路由(Router)自动生成 URL 模式 |
| 代码复用性 | 低,需手动实现每个 HTTP 方法 | 高,继承通用操作(如 ModelViewSet) |
| 适用场景 | 自定义逻辑复杂的接口 | 标准 CRUD 操作或资源管理 |
b. 适用场景对比
- 使用
APIView的场景
- 需要完全自定义请求处理逻辑
当接口逻辑复杂,无法通过通用操作实现时,使用APIView更灵活。
示例:多表联合查询、复杂权限校验、第三方 API 集成。 - 处理非标准 RESTful 请求
当接口不遵循标准的 CRUD 模式时(如批量操作、状态机转换)。
示例:一次性创建多个资源、触发特定业务流程。 - 需要精细控制请求 / 响应流程
当需要自定义序列化、认证或异常处理逻辑时。
示例:处理文件上传、实现自定义限流策略。
- 使用
ViewSet的场景
- 标准 RESTful 资源管理
当接口需要实现完整的 CRUD 操作时,使用ViewSet可大幅减少代码量。
示例:用户管理、工单系统、配置项管理。 - 快速构建 API
当需要快速搭建原型或接口遵循标准模式时,利用路由自动生成 URL。
示例:基于模型的简单增删改查接口。 - 资源关系明确的场景
当资源间存在嵌套关系(如/projects/{id}/tasks/),可结合嵌套路由使用。
示例:项目 - 任务、组织 - 用户等层级关系。
c. 实战案例对比
- APIView 示例:复杂业务逻辑接口
# views.py
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import status
from django.db.models import Q
class SearchUsersAPIView(APIView):
"""
复杂搜索接口:支持多条件筛选、分页和排序
"""
def get(self, request):
# 解析查询参数
query = request.query_params.get('q', '')
min_age = request.query_params.get('min_age')
max_age = request.query_params.get('max_age')
# 构建复杂查询
users = User.objects.all()
if query:
users = users.filter(
Q(username__icontains=query) |
Q(email__icontains=query)
)
if min_age:
users = users.filter(age__gte=min_age)
if max_age:
users = users.filter(age__lte=max_age)
# 自定义分页和序列化
serializer = UserSerializer(users, many=True)
return Response(serializer.data)- ViewSet 示例:标准用户管理接口
# views.py
from rest_framework import viewsets
from .models import User
from .serializers import UserSerializer
class UserViewSet(viewsets.ModelViewSet):
"""
自动提供 list、create、retrieve、update 和 destroy 操作
"""
queryset = User.objects.all()
serializer_class = UserSerializer
permission_classes = [IsAuthenticated] # 统一权限控制# urls.py(自动生成路由)
from rest_framework import routers
from .views import UserViewSet
router = routers.DefaultRouter()
router.register(r'users', UserViewSet)
urlpatterns = router.urlsd. 高级技巧:混合使用 APIView 和 ViewSet
- 在 ViewSet 中自定义操作
使用 @action 装饰器为 ViewSet 添加自定义 APIView 风格的方法:
class UserViewSet(viewsets.ModelViewSet):
queryset = User.objects.all()
serializer_class = UserSerializer
@action(detail=True, methods=['post']) # 自定义 POST 操作
def reset_password(self, request, pk=None):
"""重置用户密码(复杂业务逻辑)"""
user = self.get_object()
old_password = request.data.get('old_password')
new_password = request.data.get('new_password')
# 复杂密码验证逻辑
if not user.check_password(old_password):
return Response({'error': '旧密码错误'}, status=400)
if len(new_password) < 8:
return Response({'error': '密码长度不足'}, status=400)
user.set_password(new_password)
user.save()
return Response({'status': '密码已重置'})- 基于 APIView 构建基础视图,再封装为 ViewSet
当需要复用自定义 APIView 的逻辑时,可通过继承构建 ViewSet:
class CustomAPIView(APIView):
def get(self, request):
# 自定义复杂逻辑
return Response(...)
class CustomViewSet(viewsets.ViewSet):
def list(self, request):
return CustomAPIView.as_view()(request)e. 选择建议:从需求出发
- 优先考虑 ViewSet
对于标准 RESTful 资源,直接使用ModelViewSet配合路由,可大幅提高开发效率。 - 使用 APIView 处理特殊场景
当接口逻辑复杂、不遵循标准模式或需要精细控制时,使用APIView。 - 灵活组合两者
在同一项目中,可根据接口特性混合使用APIView和ViewSet,甚至在 ViewSet 中嵌入自定义 APIView 逻辑。
f. 总结:设计权衡
| 场景 | 推荐选择 | 理由 |
|---|---|---|
| 标准 CRUD 接口 | ViewSet | 自动生成路由,代码量少,符合 RESTful 规范 |
| 复杂业务逻辑接口 | APIView | 完全控制请求处理流程,便于实现自定义逻辑 |
| 资源嵌套关系(如 /parent/{id}/child/) | ViewSet + 嵌套路由 | 简化嵌套资源的 URL 配置和处理逻辑 |
| 需要与第三方系统集成 | APIView | 灵活处理非标准请求 / 响应格式,便于集成外部服务 |
| 快速原型开发 | ViewSet | 最短时间内搭建完整 API |
在实际开发中,建议根据接口的复杂度和复用性需求灵活选择。大多数标准资源管理接口可使用 ViewSet,而涉及复杂业务流程的接口则适合用 APIView 实现。
2. 其他系统功能
2.1 权限Permissions
2.2 认证Authentication
Django REST Framework(DRF)框架之认证Authentication与权限Permission
2.3 其他新功能
请参考以下博客:
Django rest Framework入门 五 :认证、权限、限流、分页和过滤-腾讯云开发者社区-腾讯云
Django的DRF(三):其他功能(认证、权限、限流、分页、过滤、排序、异常处理、接口文档)_django drf curd-CSDN博客
3. 致谢
再次感谢所有被引用内容的原作者,你们的分享为技术社区提供了宝贵的知识财富。如有标注疏漏,请随时联系笔者补充修正。




